Verifiable Inference: How Cluster Protocol and Phala Network Close the Last Gap in the AI Stack
Jun 17, 2026
11 min Read
Verifiable Inference: How Cluster Protocol and Phala Network Close the Last Gap in the AI Stack
*A technical and market deep dive into confidential AI infrastructure, the trust boundary problem, and what changes when 500+ models become verifiably private.*
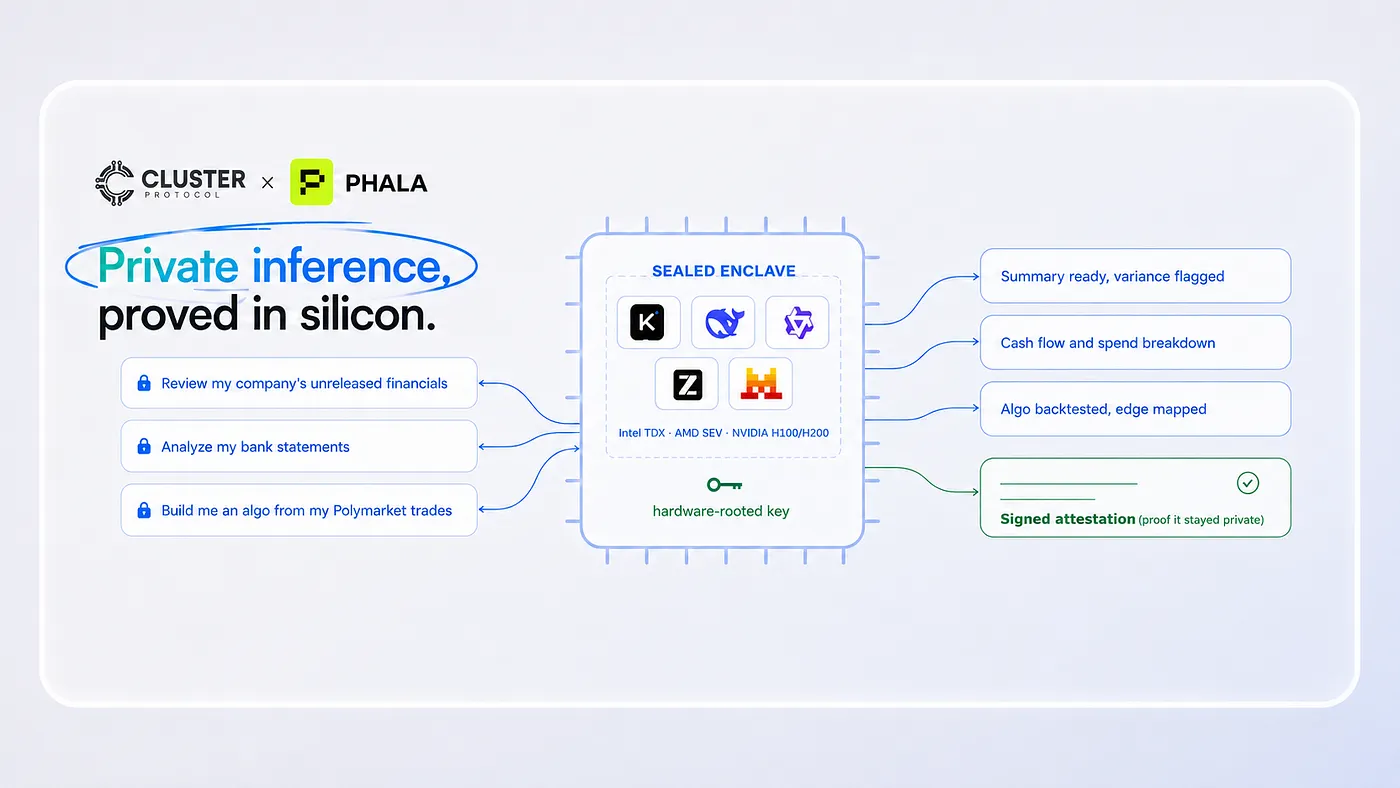
Cluster x Phala in one paragraph
Cluster Protocol is a unified AI infrastructure layer on Base that serves 500+ open-source models through a single OpenAI-compatible API, alongside a tokenized data marketplace and GPU compute provisioning.
Phala Network operates confidential AI infrastructure: it runs model inference inside hardware Trusted Execution Environments (TEEs) and returns a cryptographic attestation with every response, proving the prompt was processed inside a sealed enclave that no operator could read.
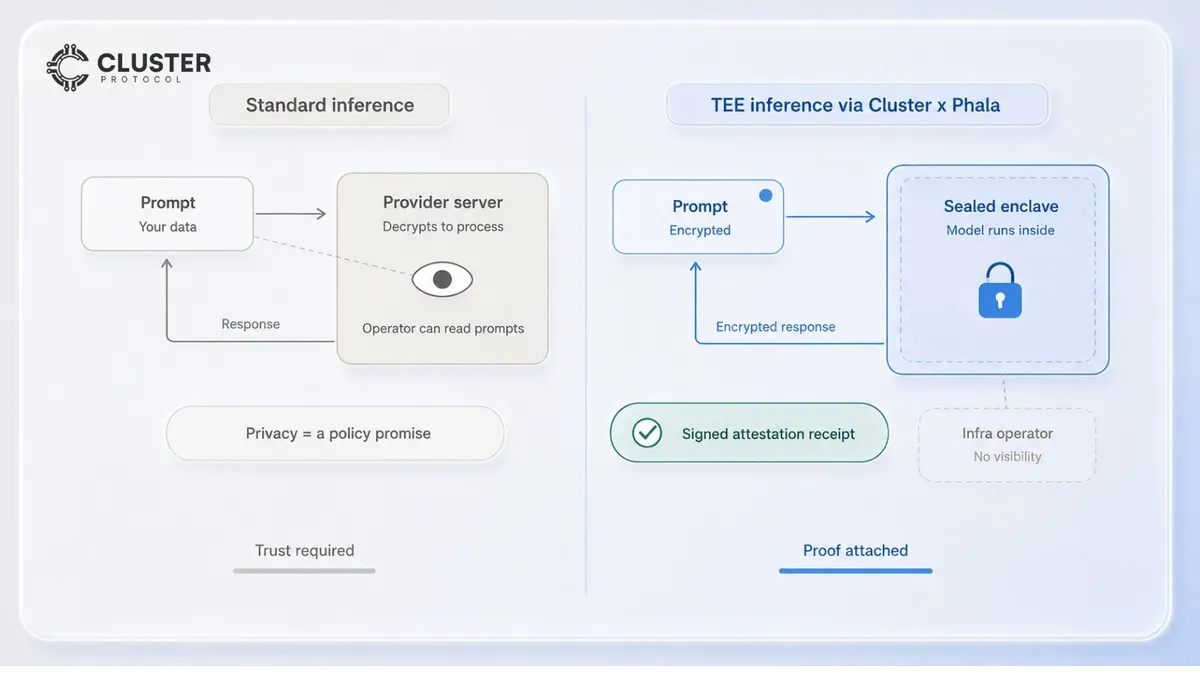
Cluster has integrated Phala’s TEE-backed inference endpoints into its model catalog. The result: a developer calling Cluster can now route any supported model through Phala’s confidential compute, getting a verifiable privacy guarantee on the inference layer without changing a line of SDK code. This is the difference between an AI provider saying “we don’t log your prompts” and an AI provider handing you a hardware-signed receipt that proves it.
The market context: why this matters now
Every crypto cycle has a demand narrative. In 2017 it was ICOs. In 2020 to 2021 it was DeFi and NFTs. The structural demand driver of this cycle is AI infrastructure, and unlike prior cycles, it is anchored in real revenue from users who are not crypto-native.
The numbers behind that shift are not subtle. AI-related DePIN now dominates the decentralized infrastructure sector by market capitalization, and the consensus across institutional research (Grayscale, Messari, Delphi, Four Pillars) is that the bulk of future AI demand comes not from training frontier models, which stays concentrated in a handful of labs, but from inference, which is distributed, latency-sensitive, and constant.
Inference is the workload that runs every time anyone uses an AI product. It is the metered, repeating, revenue-generating layer of the entire AI economy. But there is a structural problem sitting underneath all of it, and it is the reason enterprise AI adoption keeps stalling: the inference trust gap.
When you send a prompt to any standard AI API, you are not just sending a question. You are sending your proprietary data, your users’ personal information, your competitive strategy, and your compliance exposure to a server you cannot inspect, operated by a company whose only assurance is a privacy policy. McKinsey’s latest enterprise survey found data security concerns around generative AI rose 10 percent year-over-year, and they are now the single most cited barrier to deployment. The bottleneck is not whether the models are good enough. They are. The bottleneck is that the most valuable AI workloads run on the most sensitive data, and that is precisely the data enterprises cannot responsibly hand to a black box.
This is the gap Cluster and Phala close together. And the way they close it is worth understanding precisely, because the precision is the entire point.
What a Trusted Execution Environment actually is
A TEE is a region of a processor that is isolated by the silicon itself. Code and data inside it are protected from the operating system, the hypervisor, the cloud provider, and every other process on the machine. The isolation is not enforced by software permissions that an administrator could override. It is enforced by the CPU, and increasingly the GPU, at the hardware level.
*Two implementations matter for AI inference:*
- Intel TDX (Trust Domain Extensions) creates confidential virtual machines, called Trust Domains, whose memory is encrypted and inaccessible to the host. AMD offers an equivalent with SEV-SNP. These protect the CPU side of a workload.
- NVIDIA Confidential Computing extends the same principle to the GPU, where the actual model inference runs. On H100, H200, and Blackwell hardware, the GPU memory holding model weights and activations is encrypted and isolated.
Phala combines both: TDX-encrypted CPU memory plus NVIDIA-Confidential GPU memory, so the entire inference path, from the request entering the machine to the model computing the response on the GPU, stays inside a hardware-sealed boundary.
The mechanism that makes this verifiable rather than merely private is attestation. Before any workload runs, the TEE hardware generates a quote: a cryptographic document containing measurements of the CPU’s trusted computing base, the operating system image, and the application code, signed by a key fused into the processor by the manufacturer. On Intel TDX, this quote is produced by a dedicated Quoting Enclave and includes the MRTD (the measurement of the Trust Domain) and RTMR registers (runtime measurement registers that record what code was loaded). A verifier checks the signature against Intel’s root certificates. If it validates, you have mathematical proof that a specific, unmodified piece of code ran inside genuine secure hardware. Not a claim. A proof.
This is the conceptual shift, and it is best captured by an old line that Phala itself invokes: trust, but verify. For forty years that was an aspiration. With TEE attestation, the verify part becomes a curl command.
How the integration actually works, end to end
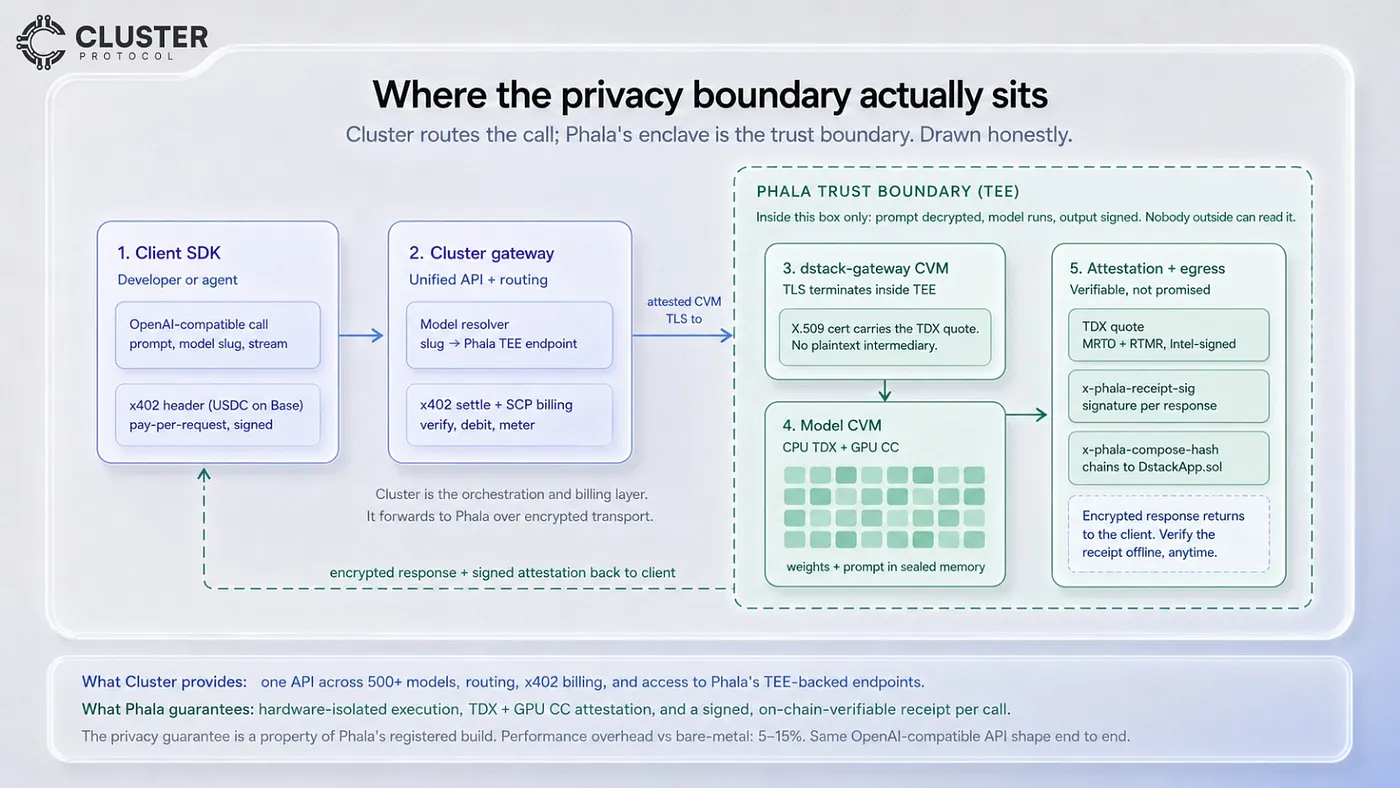
Here is the precise path a request takes, and it is worth being exact about which party does what, because the integrity of the privacy claim depends on it.
A developer or an autonomous agent makes an OpenAI-compatible call to Cluster’s API: a prompt, a model slug, optional tools, and an x402 payment header carrying USDC on Base. Cluster’s gateway is the orchestration and billing layer. It resolves the model slug to the right backend, verifies and settles the x402 payment, meters usage in $CP, and forwards the request over encrypted transport to Phala’s confidential infrastructure.
The trust boundary begins at Phala. This is the part that matters, and it is genuinely elegant in Phala’s design. The request does not hit a plaintext relay. Phala uses a component called dstack-gateway, which is itself a confidential VM whose X.509 TLS certificate carries its TDX quote. The TLS session terminates inside that attested enclave. From there it passes to the model CVM, another confidential VM, where the prompt is finally decrypted inside hardware-protected memory, the model weights are loaded, and inference runs on the GPU under NVIDIA Confidential Computing. There is no point along this path where an operator holds the plaintext prompt outside an attested enclave.
When inference completes, the response is encrypted before it leaves the enclave, and Phala attaches proof. Every response carries an x-phala-receipt-sig header (a signature over the response, chaining to the TDX hardware root) and an x-phala-compose-hash header (a fingerprint of the exact build that ran, which is registered on-chain in a DstackApp.sol contract). This means anyone can verify, offline and after the fact, that the build which produced their answer is the build that was publicly registered, running in genuine TEE hardware, with no logging. The no-log property is not a policy line in a terms-of-service document. It is a property of the registered build: the container composition has no log volumes and no telemetry, and the build can be revoked onchain to kill access globally. The performance cost of all this is between 5 and 15 percent overhead versus bare-metal, depending on model size and hardware generation. That is the entire price of hardware-enforced, cryptographically verifiable privacy. No accuracy tradeoff. No architecture change. The API shape is identical end to end.
What Cluster contributes to this is the part that makes it usable at scale: a single API across 500+ models, unified routing, x402-native agent billing, and the integration work that turns Phala’s confidential endpoints into just another model you can select. What Phala contributes is the part that makes it trustworthy: the hardware isolation, the attestation, and the on-chain-verifiable receipt. Neither half delivers the full proposition alone. Together they make verifiable private inference a default option across a frontier-scale model catalog.
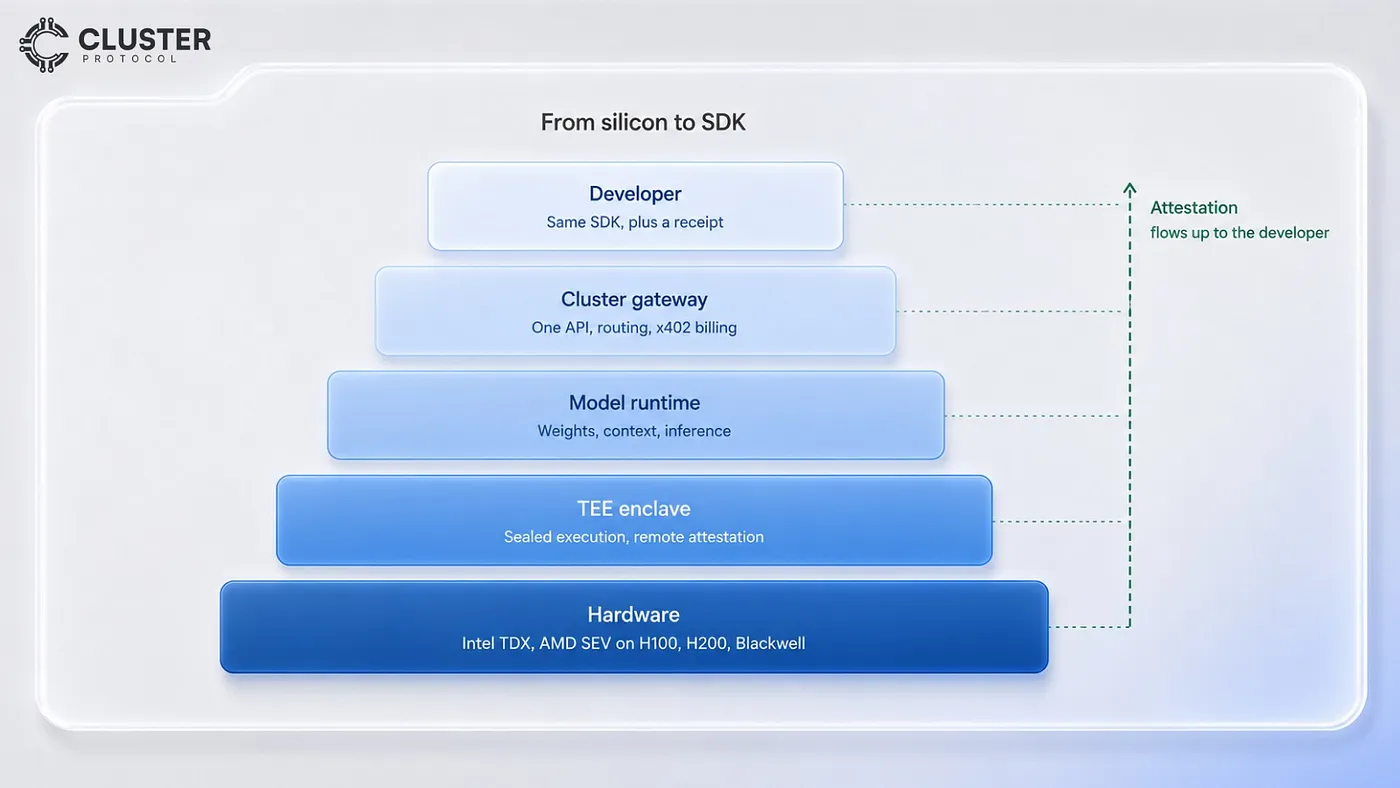
What’s behind the scenes
It is worth stating plainly where the guarantee starts and stops, because overclaiming here would defeat the purpose of a privacy product. Cluster is the orchestration and billing layer. It is in the request path. The hardware privacy guarantee, the part that is cryptographically provable, applies to the inference execution inside Phala’s enclaves, and the attestation receipt proves exactly that and nothing more. This is not a weakness of the architecture. It is the correct way to describe it, and any serious technical evaluator (a security researcher, an exchange’s due-diligence team, an enterprise’s compliance officer) will respect a precise claim and immediately distrust an inflated one.
The strength of the integration is that it brings a genuine, verifiable privacy primitive to a 500+ model catalog through one API. That is a real and significant thing. It does not need to be dressed up as something it is not. There is also a limit worth being candid about, one Phala itself acknowledges: no infrastructure-layer technology can prevent a user from putting sensitive data into a prompt that is then sent, through an authorized channel, somewhere it should not go. TEEs guarantee that the inference runtime cannot leak your data. They cannot govern what an application chooses to do with the model’s output. Verifiable inference is a powerful guarantee about the compute layer. It is not a substitute for sensible application design.
The model coverage, and why each tier matters
The integration is not a curated shortlist of “privacy models.” It brings the privacy primitive to the same catalog developers already use on Cluster. The tiers map to real use patterns. The open-source frontier: DeepSeek V4 Pro and Flash, Llama 3.3 70B, Qwen3 235B, Mistral Small 3.2, Gemma 431B, Nemotron Cascade 2, Kimi K2–6, MiniMax M27, Hermes 3 405B.
These are the workhorses for production reasoning, code generation, and analysis. Running them inside TEEs means the prompts driving sensitive workloads (proprietary code review, internal document analysis, financial modeling) never leave hardware isolation. Phala’s catalog already spans coding, reasoning, general chat, and open-weight families from DeepSeek, Qwen, Meta, Mistral, Google, and OpenAI’s open releases, so this coverage is real, not aspirational. The E2EE tier: GLM 5–1, Qwen3 5–122B, GPT-OSS 120B, Venice Uncensored 24B and others, where end-to-end encryption in transit combines with TEE isolation in use. Encryption protects data in motion; the TEE protects data during processing. Together they close the full chain, the exact combination Venice AI shipped on Phala’s infrastructure for its private inference mode. Uncensored models: for red-teaming, security research, medical and legal analysis, where content filtering interferes with legitimate work, running uncensored models inside TEEs pairs unrestricted output with verifiable privacy, two properties that are individually available but rarely combined.
The GLM series and cross-jurisdiction models: the full Z-AI and ZAI-Org GLM family. Chinese-ecosystem models running in Western TEE hardware with cryptographic attestation is not just an inference option, it is a compliance architecture for teams operating across regulatory boundaries.
Why this is structurally bullish for open-source AI
There is a second-order consequence here that is easy to miss and important to state.
The standard argument against open-source models in the enterprise is not about capability. It is about operational and compliance overhead. To use an open model privately, you either self-host (expensive, complex) or use a third-party API (which reintroduces the trust problem). So enterprises default to the large closed providers, not because the models are better, but because the vendor-management and compliance story is simpler.
Verifiable inference collapses that argument. An enterprise can now use DeepSeek V4 Pro or Llama 3.3 70B through a standard API (Cluster), with hardware-enforced privacy (Phala TEE), and a cryptographic attestation that satisfies the “appropriate technical measures” language in GDPR Article 32 and equivalent regimes. The compliance officer gets a TDX quote instead of a vendor’s promise. The principle of technical impossibility, where the processor genuinely cannot read the data even under subpoena, is a stronger legal position than “we promise not to look.”
The models were always good enough. The missing piece was provable privacy at the infrastructure layer. Once any open-source model can run inside an attested TEE, the entire open ecosystem becomes enterprise-deployable.
Cluster’s integration with Phala effectively turns its 500+ model catalog into compliance-ready, privacy-verified inference, accessible through one API. That is a structural tailwind for open-source AI adoption, and Cluster is positioned at exactly the layer that captures it.
The agent economy angle
The forward-looking case is stronger still. Institutional research across Delphi, a16z, and Coinbase converges on the same prediction: AI agents become major economic participants, transacting autonomously, which requires two new primitives, machine-native settlement and verifiable agent identity. This is the world that x402 (HTTP-native per-request payments) and ERC-8004 (agent identity) are being built for.
Verifiable private inference is the third primitive that economy needs, and it is the one least discussed. An autonomous agent’s prompt history is a complete record of its strategy, its knowledge, and its intent. An agent that pays for inference through a transparent rail while exposing its prompts to the inference provider has leaked its entire edge. Combine x402 with TEE inference and you get something that did not exist before: an agent that pays for inference autonomously, settles on Base, and where neither the payment rail nor the inference provider can see what the agent is doing, with a cryptographic receipt proving the execution was private. Request, payment, private execution, settlement, proof, all trustless, no human in the loop.
That is not a feature. It is a precondition for an agent economy where agents compete and transact without surrendering their strategies to the infrastructure they run on. Cluster sits at the intersection of all three primitives: the 500+ model inference layer, the x402 payment rails, and now, through Phala, the verifiable privacy layer.
The bottom line
The AI infrastructure stack is converging on a clear truth: capability without verifiable privacy is a liability, and the inference layer is where that liability concentrates, because inference is where the sensitive data meets the model.
Cluster Protocol provides the capability and the access: 500+ models, one API, tokenized data, GPU compute, x402 agent payments, all on Base. Phala Network provides the proof: hardware-isolated TEEs, combined CPU and GPU attestation, a signed and onchain-verifiable receipt per inference, processing over a billion tokens a day in production.
Integrated, they let a developer stop choosing between power and privacy. The same API call, settled in the same token, on the same chain, now comes with a cryptographic receipt that proves the inference was private. The market is moving toward real revenue, real compliance, and an agent economy that needs all three new primitives at once. Cluster is positioned at the layer where those forces meet.
The era of “trust us, we don’t log your prompts” is ending. The era of “here is the quote, verify it yourself” has started.
Build with verifiable private inference: [hub.clusterprotocol.ai](hub.clusterprotocol.ai)
Ship on-chain applications from a prompt: [app.codexero.xyz](app.codexero.xyz)
Phala’s confidential AI infrastructure: [phala.network](phala.network)
*Cluster Protocol is a unified AI infrastructure layer on Base, serving 500+ models through a single API with a tokenized data marketplace, GPU compute, and x402 agent payment rails. $7.75M raised from DAO5, Paper Ventures, Mapleblock Capital, and JPEG Trading.*
*This piece describes a technical integration. The privacy guarantees described are those provided by Phala Network’s TEE infrastructure on the inference layer; Cluster Protocol provides the unified API, routing, and settlement layer. Claims about hardware attestation reflect Phala’s publicly documented architecture*