Training Without Consent: Why the AI Boom Owes Creators
Jun 7, 2025
9 min Read

TL;DR
1. Creators’ Work is Exploited: AI models are trained on vast amounts of unlicensed creative content without consent or compensation.
2. Attribution is the Key Issue: AI lacks transparency, making it hard to trace and fairly compensate contributors.
3. Payable AI is the Solution: AI should pay for training data, just like music streaming platforms pay royalties.
4. Emerging Tech Can Help: Influence Functions, Gradient-Based Tracking, and LoRA models could enable fair attribution.
5. General AI vs. Specialized AI: Industry-specific AI models offer better accuracy and accountability.
6. OpenLedger Monetizes AI Data: A decentralized marketplace can reward data contributors fairly.
7. Cluster Protocol Enables AI Economy: It provides AI developers with monetization and seamless AI-building infrastructure.
The Silent Theft of Creative Work
*Creators’ Work is Exploited:* *AI models are trained on millions of copyrighted books, artworks, and research papers and none of it licensed, and none of it compensated.*
The internet has always thrived on the backs of creators: writers, musicians, filmmakers, researchers, and artists. Their work has built industries, driven engagement, and fueled the platforms we use daily. But now, in the age of AI, their intellectual labor is being exploited at an unprecedented scale.
Tech giants have indiscriminately scraped vast amounts of data, training AI models on everything from classical literature to modern scientific research without consent or compensation. This is not a minor oversight; it is a direct threat to creative industries. AI-generated content is flooding markets, displacing human creators while being built on their past works.
There are about millions of patents in the world but less than just 0.001% is litigated, showing the vastly whitespace of IP laws being undermined. And even are litigated, just over 5% are settled in the court.

OpenAI’s GPT models were found to be trained on Books3 : A dataset of over 180,000 pirated books. Some were bestsellers. None were licensed.
The worst part? Creators are powerless.
- They don’t own the infrastructure.
- They can’t audit what data was used.
- They have no legal recourse in most jurisdictions.
- And once their intellectual property has been absorbed into an AI model, it cannot be removed.
The AI industry has committed its “original sin” by training on unlicensed data then telling creatives to simply “move on.” But what if, instead of lawsuits, there was a way to fight back through economic incentives?
This debate isn’t just theoretical, it’s already playing out on the world stage. In a recent discussion in the British Parliament, creators pushed for tech giants to acknowledge and compensate them for AI training data. While a tech industry figure insisted that the damage had already been done and creators should move on, a joint committee of MPs heard strong opposition from publishers and a composer outraged by the unchecked exploitation of copyrighted material. The debate highlighted a growing frustration: AI companies are profiting from creative works without consent or compensation, and many believe it’s time for a fairer system.
**Need for Fair Compensation**
A future where AI and creators can coexist doesn’t have to be a fantasy. It starts with Payable AI, a system where creators are fairly compensated for their contributions. Here’s how it could work:
1. AI Should Pay for Training Data
Models should only be trained on licensed, consented data.
If AI benefits from a creator’s work, that creator should receive royalties—just like the music industry’s streaming model.
2. Transparency & Auditability
Creators should be able to see if their work was used in training datasets.
Blockchain or similar technology could help track data usage and payments.
3. Opt-In, Not Opt-Out
Instead of forcing creators to fight to remove their work, AI companies should require explicit permission before using content.
4. AI-Generated Content Should Be Labeled
Consumers deserve to know when they’re engaging with human work versus AI-generated material.
Clear labeling helps prevent market dilution and protects creative authenticity.
The battle for creative rights in the AI age is not just about fairness—it’s about preserving culture itself. If AI is going to shape the future, it must do so with creators, not against them.
**AI Struggles with Fair Data Attribution**
For AI to fairly compensate creators, it must first answer a deceptively simple question: Who contributed what?

Modern AI models ingest vast amounts of data such as text, images, audio etc. blending them into a neural representation that makes individual contributions nearly impossible to trace. If an AI writes a poem in the style of Sylvia Plath, was it trained on her works? On similar poets? On fan fiction inspired by her? The AI industry has largely avoided these questions, making data attribution one of the hardest problems in AI ethics.
The obvious solution would be paying a flat fee for access to data that falls apart under scrutiny:
- It undervalues long-term contributions. A dataset that significantly improves a model should be worth more than one that has little impact.
- It lacks transparency. Creators don’t just want a payout; they want to understand how their work is being used.
While AI companies claim that attribution at scale is impossible, recent research suggests otherwise.
Emerging techniques could provide a path forward, making attribution practical for Payable AI. Some key advancements include:
1. Influence Functions & Shapley Values
Influence Functions analyze how changes in training data impact a model’s predictions, while Shapley Values measure the marginal contribution of each data point to an outcome.
- These methods estimate how much individual data points contribute to a model’s performance.
- However, they struggle to scale to the trillion-token datasets used by AI giants.
2. Gradient-Based Tracking
- Tracks how specific training data influences model outputs.
- Promising but computationally expensive at scale.
3. The Rise of LoRA-Tuned Models
- Smaller, fine-tuned AI models allow for more precise attribution.
- Instead of generalist AI, domain-specific models could enable clearer data tracking and compensation.
- LoRA (Low-Rank Adaptation) models optimize AI by fine-tuning only a small subset of parameters, making them more efficient and adaptable while maintaining traceability.
The shift from monolithic AI to domain-specific, traceable AI can be the key to making Payable AI a reality. With proper incentives, attribution can move from an “unsolvable problem” to an industry standard, ensuring that AI benefits everyone, not just the companies training it.
**Why Hugging Face Falls Short on Fair AI Monetization**
Hugging Face is widely celebrated as the open-source hub for AI, providing free access to models, datasets, and research. It has democratized AI development, making cutting-edge technology accessible to researchers and developers worldwide. However, there’s a critical flaw in this model: contributors don’t get paid.
While companies leverage Hugging Face’s resources to build and commercialize AI products, the researchers and data providers who fuel these innovations see little to no financial return. The platform facilitates collaboration but does not embed economic incentives for contributors. This creates a system where enterprises extract value, while the actual creators remain uncompensated.
The issue ties back to AI attribution. As discussed earlier, tracking contributions is key to fair compensation. Without a mechanism to quantify and distribute earnings based on impact, Hugging Face’s open-source ethos remains incomplete.
**A New Economic Model for AI Data**

This is where projects like OpenLedger enters the conversation as a fundamental rethinking of how AI data should be valued, traded, and compensated.
AI today is built on unpaid labor, with models trained on vast amounts of data collected without consent or compensation. OpenLedger tend to embeds financial incentives directly into AI’s economic fabric.
Instead of treating data as a one-time commodity, it claims to ensure that contributions generate continuous value. Think of it like YouTube’s Partner Program but for AI training data. On YouTube, creators don’t sell their videos outright; they earn revenue indefinitely based on engagement.
The solution applies the same concept to datasets, ensuring that contributors, whether they provide legal documents, climate research, financial analytics, or curated code libraries, receive micropayments whenever their data influences an AI model’s output.
Unlike Hugging Face, the solution integrates monetization at the protocol level, ensuring data contributors are rewarded. Key differences include:
1. Payments for Contributions
Every dataset, model, or insight shared generates revenue.
2. Decentralized AI Marketplace
Data isn’t just freely available, it’s a tradeable asset where continuous revenue streams replace one-time licensing deals.
3. Incentive-Driven AI Innovation
A sustainable model encourages high-quality contributions from researchers and creators who benefit from AI’s commercial success.
**Specialized AI vs. General AI**
One of the biggest myths in AI today is that larger models automatically mean better intelligence. Tech giants like OpenAI, Google, and Meta are locked in an arms race, building massive general-purpose AI systems designed to do everything from writing essays to diagnosing medical conditions. But scale alone doesn’t make AI smarter, it just makes it broader.

Think of human expertise. If every lawyer, doctor, and engineer learned from the same generic textbook, their knowledge would be shallow and incomplete. You wouldn’t trust a neurosurgeon who trained using a general science book that also covered chemistry and astronomy. The same principle applies to AI.
Businesses don’t need an AI that knows a little about everything; they need an AI that deeply understands their specific industry.
The problem of non-payable AI is only made worse by the way AI models are trained. As discussed earlier, creators’ work has been used without compensation, and data attribution remains a major ethical challenge. General AI models scrape the internet indiscriminately, absorbing information without properly valuing or compensating those who produced it. This approach not only harms creators but also limits AI’s potential.
This is where specialized AI thrives. Instead of relying on massive, vague datasets, specialized AI models are trained on domain-specific, high-quality data that is properly valued and compensated.

**Scaling Payable AI: The Bottlenecks of Attribution and Adoption**
Scaling Payable AI comes with formidable technical and market challenges. While attribution works in smaller, fine-tuned models, applying it to trillion-token giants like GPT-4 is an entirely different beast. AI must evolve past its current “black box” nature for true data accountability.
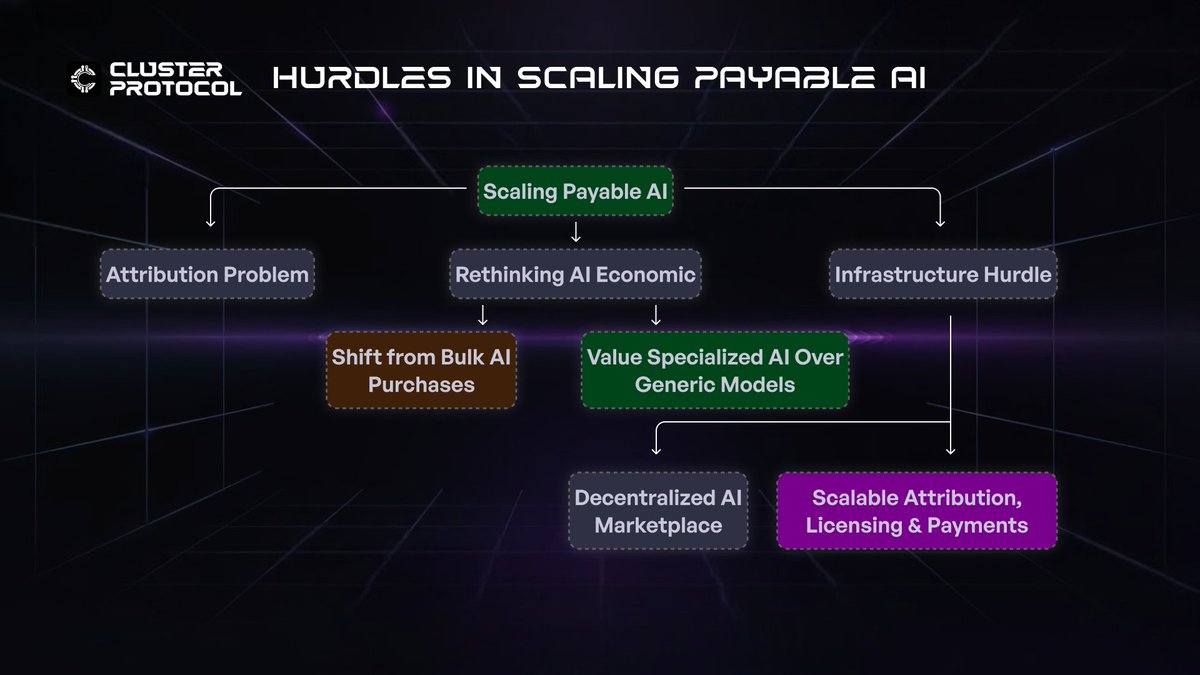
1. The Attribution Problem
Tracking which datasets influence AI decisions is an unsolved puzzle at scale. Influence Functions, Shapley Values, and gradient-based tracking offer partial solutions, but they buckle under the weight of massive models. LoRA-tuned AI presents a path forward allowing fine-tuned, domain-specific models to maintain traceability, but it’s still not 100% or near perfectly accurate.
2. Rethinking AI Economics
Businesses are accustomed to buying AI in bulk and paying a flat fee for access rather than per inference. The shift to Payable AI requires a new mindset: valuing high-quality, specialized AI outputs over generic, one-size-fits-all models. This is an economic and cultural shift that won’t happen overnight.
3. The Infrastructure Hurdle
Building a decentralized AI marketplace isn’t just about payments, it requires scalable, secure, and efficient systems for attribution, licensing, and microtransactions. OpenLedger needs to provide a seamless experience where enterprises naturally prefer fairly compensated AI over current exploitative alternatives. The technology is catching up, but adoption will take time.
**The Future of AI: Who Gets Paid, Who Gets Left Behind?**
The rise of AI has exposed a deep flaw in the system: the people who built the knowledge economy, writers, researchers, artists are being pushed aside while tech giants cash in. Payable AI isn’t just about compensation; it’s about recognizing that intelligence, whether human or artificial, is nothing without the data that fuels it.
For too long, AI has been a one-way street: creators give, AI takes. But what if that changed? What if every contribution to AI, every dataset, every model, every insight became an asset that generates value over time?
The unchecked use of creative work to train AI models without consent or compensation has exposed a critical gap in current copyright and remuneration systems, leaving creators largely powerless.
Solutions like Payable AI-where AI companies pay for licensed data, ensure transparency, and allow creators to opt in-are gaining traction as fair and pragmatic alternatives to litigation.
Emerging attribution technologies and decentralized marketplaces promise a future where creators are rewarded for their contributions, but the transition will require legal reforms, industry cooperation, and robust frameworks to ensure fair compensation and transparency for all creative workers.
About Cluster Protocol
Cluster Protocol is making intelligence co-ordinated, co-owned & trustless.
Our infrastructure is built on two synergistic pillars that define the future of decentralized AI:
Orchestration Infrastructure: A permissionless, decentralized environment where hosting is distributed, data remains self-sovereign, and execution is trust-minimized. This layer ensures that AI workloads are not only scalable and composable but also free from centralized control.
Tooling Infrastructure: A suite of accessible, intuitive tools designed to empower both developers and non-developers. Whether building AI applications, decentralized AI dApps, or autonomous agents, users can seamlessly engage with the protocol, lowering barriers to entry while maintaining robust functionality.
🌐 Cluster Protocol's Official Links: