The Road to Autonomous AI
Jul 3, 2025
10 min Read

TL;DR
AI’s Limitations – AI lacks full autonomy due to reliability, real-time data, and contextual memory challenges.
Reliability Issues – Bias and hallucinations reduce trust in AI for high-stakes tasks.
Mira Network – Uses decentralized verification to improve AI accuracy and reduce errors.
Real-Time Data Gap – AI models struggle with adapting to live data due to access restrictions.
Masa’s Subnet 42 – Enables real-time AI feeds through decentralized data aggregation.
Memory Constraints – AI lacks persistent memory, limiting long-term learning.
Cluster Protocol – Provides AI infrastructure, monetization, and pre-built templates for developers.
Future of AI – Bridging these gaps is key to achieving true AI autonomy.
AI is often dubbed as the internet of our age or the next big “thing” in the history of humankind, yet the full potential of AI remains elusive. While AI excels in specific applications, it is still not capable of handling critical global transactions or making high-stakes decisions without human oversight.
Despite the rapid advancements in machine learning and neural networks, AI continues to face inherent limitations that prevent it from becoming truly independent.
The promise of AI autonomy has long captured the imagination of researchers and engineers, but the complexities involved in achieving true self-sufficiency are far greater than anticipated.
Current AI systems operate within predefined constraints, relying on statistical models and historical data to generate outputs.
This reactive nature means they lack genuine decision-making abilities required for unsupervised, high-stakes tasks. The gap between theoretical AI capabilities and real-world deployment remains vast, as
AI still struggles with adaptability, uncertainty, and accountability in complex environments.
Despite the rapid advancements in machine learning and neural networks, AI continues to face inherent limitations that prevent it from becoming truly independent.
Missing puzzle pieces for Autonomous AI

Reliability: We can’t trust AI systems with everything.
Real-Time Data: AI needs to know what is happening in real time.
Contextual knowledge: Ai must remember beyond a single interaction and prompt.
1. The Reliability Problem
AI has a fundamental flaw that prevents it from reaching its revolutionary potential. While AI excels at generating creative and plausible outputs, it struggles to provide error-free, reliable results. This limitation confines AI primarily to human-supervised or “low-stake/value” operations like chatbots, preventing it from handling high-risk, real-time decisions independently.
Errors in AI can be categorized into two major types: bias and hallucinations. These issues reduce AI’s trustworthiness and limit its ability to function autonomously in critical areas like finance, healthcare, and governance.
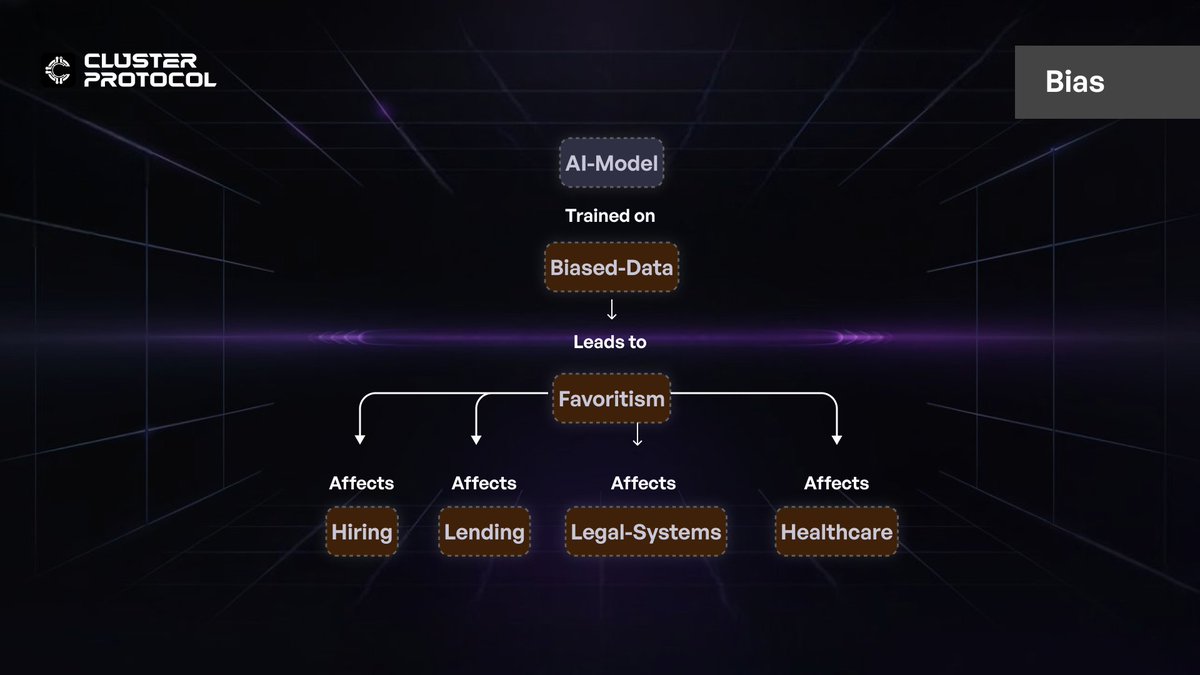
Bias
Bias in AI refers to systematic errors where models favor certain outcomes or groups due to flawed training data or algorithmic structures. If an AI is trained on data that over represents one demographic, it may unfairly favor that group. It can lead to harmful consequences in hiring, lending, legal systems, and healthcare decisions. Even with efforts to reduce bias through diverse datasets, human-labeled data and societal structures may still introduce bias.
Hallucination
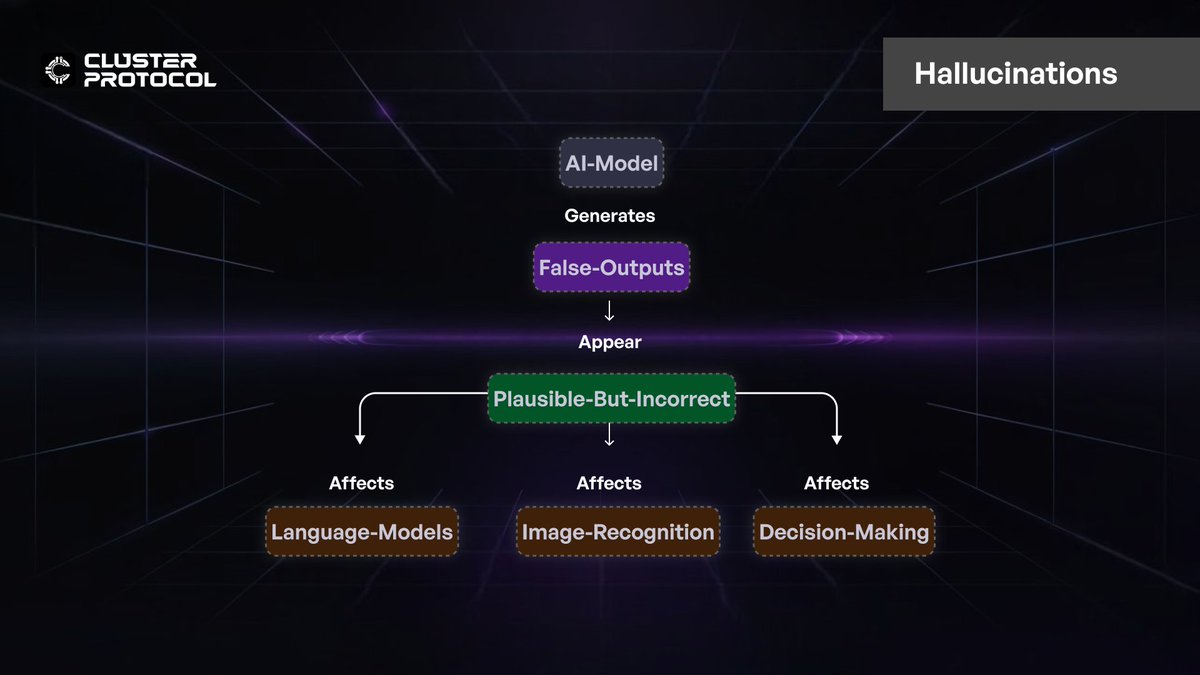
AI hallucinations occur when models generate false or misleading outputs that seem plausible but are factually incorrect. A language model might fabricate references or misinterpret a question. In image recognition, hallucinations could involve detecting objects that don’t exist. AI relies on pattern recognition rather than true understanding, making hallucinations difficult to prevent.
Addressing AI Reliability
Mira Network presents a groundbreaking solution to these challenges through a decentralized, multi-model consensus verification system. Instead of relying on a single AI model, Mira distributes AI-generated content across a network of independent validators.
These node operators cross-check statements using diverse AI models, ensuring accuracy and fairness. Mira’s crypto economic incentives encourage honest participation, penalizing deviations from consensus.
The integration of Proof-of-Verification mechanisms provides a scalable and trustless framework, making Mira a strong contender for applications in finance and healthcare.
Early results indicate that Mira’s approach reduces AI error rates from 80% to just 5%, setting a new standard for reliable AI verification.
*The question arises: can fine-tuned models alone solve these issues?*
The answer is both yes and no.
In specialized domains, fine-tuned models show greater reliability compared to broader AI systems. However, research indicates that they struggle to incorporate new knowledge effectively. Training examples that introduce novel information are often learned less efficiently than those aligning with the model’s existing knowledge.
Additionally, fine-tuned models lack adaptability when confronted with unexpected scenarios outside their training data, limiting their applicability in real-world autonomous tasks.
Accountability: Another pillar of reliable AI
The fundamental problem with AI is its error rate, which currently stands between 2-5%, depending on the model and task. While this is much better than human error rates (10-20%), it’s still not enough to trust AI with unsupervised decision-making.
Human trust and reliability stems from accountability, where institutions or individuals are held responsible for their actions.
Unlike previous technological advancements (e.g., steam engines or air travel), AI lacks clear accountability mechanisms when errors occur.
2. Need for Real-Time Data
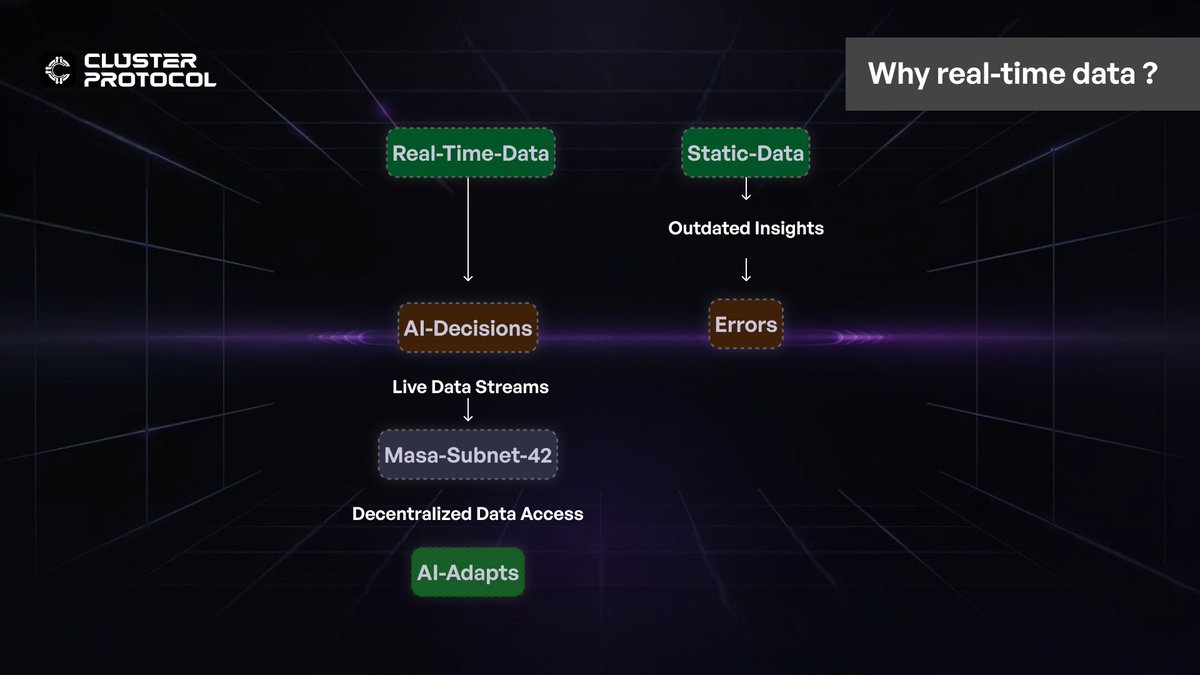
AI’s true power lies not in static models but in its ability to adapt dynamically to new information. The real world isn’t static, so AI models that rely solely on pre-trained data will always lag behind.
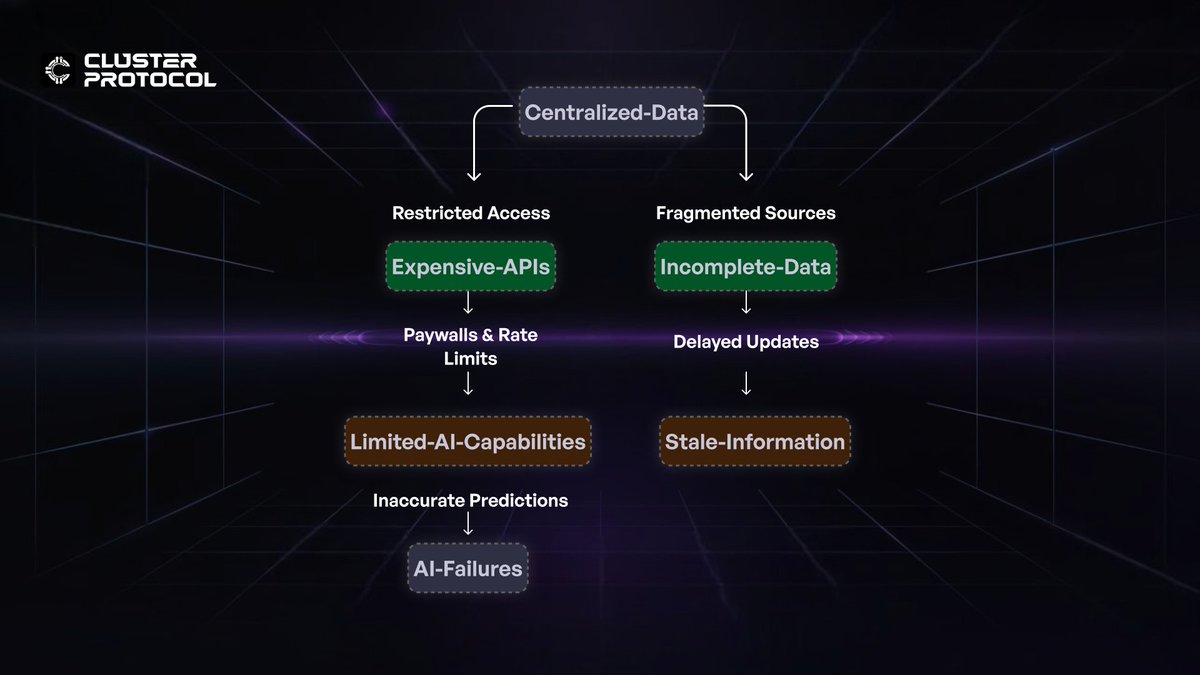
Yet, accessing live data streams isn’t as simple as flipping a switch. Many high-value data sources are locked behind paywalls, throttled by restrictive APIs, or scattered across fragmented platforms. Major platforms monetize access to their data aggressively. For instance, Twitter (now X) charges up to $42,000 per month for full API access
AI agents need a constant, unfiltered feed of insights to operate at peak efficiency, but the cost and complexity of gathering this data make it a luxury few can afford.
The issue isn’t just financial, it’s structural. Centralized platforms control the flow of information, creating bottlenecks that stifle innovation.
Masa’s Subnet 42: A New Approach to Real-Time AI Feeds
Masa is disrupting this data bottleneck with Subnet 42, an always-on, decentralized data refinery that democratizes real-time data access. Instead of relying on a handful of gatekeepers, it taps into a distributed network of data sources, constantly aggregating, refining, and delivering AI-ready insights.
This system pulls live data from platforms like Twitter, Telegram, and blockchain networks, offering an open alternative to expensive, closed APIs. The key innovation isn’t just access, it’s the incentive model. Subnet 42 rewards contributors for providing, verifying, and curating high-quality data, ensuring a self-sustaining ecosystem.
By decentralizing real-time data, Masa enables AI agents to make decisions based on fresh, unfiltered insights, drastically improving their ability to navigate complex, fast-moving environments. This isn’t just about cutting costs, it’s about creating a data infrastructure that scales with AI’s growing needs.
What Real-Time Data Unlocks for AI
Masa’s Subnet 42 reimagines real-time AI data pipelines by decentralizing both data collection and validation, contrasting sharply with traditional fine-tuning approaches that rely on centralized, static datasets. While conventional fine-tuning adjusts pre-trained models using curated historical data-a process prone to staleness and high costs due to manual aggregation-Subnet 42 leverages a global network of miners and validators to continuously scrape, verify, and deliver live data from platforms like X (Twitter), Telegram, and blockchain networks.
With unrestricted access to high-quality, real-time information, AI agents gain entirely new capabilities:
DeFi Automation: AI-driven rebalancing of portfolios, optimizing yield strategies, and detecting market anomalies.
Market Intelligence: Real-time sentiment analysis, trade monitoring, and economic trend tracking.
AI-Powered Communities: Autonomous moderation, dynamic content curation, and real-time engagement analysis.
Personalized AI Assistants: Agents that evolve with user behavior, delivering continuously refined recommendations.
3. Why AI Feels Forgetful: Context knowledge
For AI to operate independently, it must remember context beyond a single interaction. Right now, it doesn’t. Every time you talk to an AI, it starts fresh—like a person with no memory of past conversations. While this might not matter for one-off tasks, it’s a huge limitation for AI agents meant to assist over time, adapt to users, or handle complex workflows.
This isn’t a simple problem. AI memory operates very differently from human memory, relying on two distinct types: parametric memory and working memory. Each has strengths, but neither alone is enough to make AI fully contextual.
The Two Layers of AI Memory

Parametric Memory
is like a human’s long-term memory, baked into the model’s parameters during training. It contains general knowledge but doesn’t update unless the model is retrained. This is why AI can recall facts from years ago but struggles with new information that arrives after training.
Parametric memory is like a person’s long-term memory. When an AI is trained, it “learns” a huge amount of information-facts, language patterns, and general knowledge-which gets stored in its parameters. This knowledge is built in and doesn’t change unless the AI is retrained with new data. That’s why an AI can recall facts from years ago, but if something new happens after its training, it won’t know about it until it’s updated. For example, if a new scientific discovery is made after the AI’s last training session, it won’t be aware of it.
Working Memory
functions like short-term memory, holding temporary context within a session. It allows AI to keep track of recent inputs but is constrained by a token limit. Even the best models, like GPT-4, eventually forget earlier parts of a long conversation. And once a session ends, the memory is wiped clean.
This means that today’s AI agents can only “remember” in the moment. They don’t retain persistent memory unless paired with external storage systems, making long-term learning difficult.
Working memory is more like short-term memory. It helps the AI keep track of the current conversation or recent inputs within a single session. For instance, if you’re chatting with an AI, it can remember what you said earlier in the conversation, but only up to a certain point. This is because there’s a limit (called a token limit) on how much information the AI can hold at once. If the conversation gets too long, the AI starts to forget the earlier parts. And once the session ends, all that memory is wiped clean.
Why Long-Term AI Memory Changes Everything
If AI is to evolve from a tool to an autonomous agent, it must develop persistent memory. Without it, every interaction resets, making it impossible for AI to improve over time or provide personalized experiences.
Context Retention: AI needs to remember user preferences, past queries, and previous interactions. Imagine a virtual assistant that forgets your schedule every time you ask for reminders.
Efficient Information Retrieval: Instead of reprocessing the same data repeatedly, AI should store and access past insights, leading to smarter decision-making.
Continuous Learning: AI must update its memory dynamically, integrating new data without requiring full retraining. Right now, most models don’t evolve between interactions, limiting their adaptability.
For AI to reach its full potential, it must bridge the gap between short-term session memory and long-term contextual knowledge. Solving this isn’t just about better models, it’s about rethinking how AI retains and recalls information in a way that feels human-like.
Breaking the Barriers to AI Autonomy
AI’s path to true autonomy is blocked by fragmentation—models lack persistent memory, struggle with real-time adaptability, and operate in isolated environments. Without a framework to bridge these gaps, AI remains reactive rather than proactive, limiting its ability to function independently.
A unified coordination layer is essential to enable AI agents to evolve, share knowledge, and dynamically adjust to new data. By creating an interconnected ecosystem, developers can build AI that retains context, refines decision-making over time, and operates seamlessly across applications. This shift moves AI beyond static interactions toward continuous learning and adaptation.
With a transparent and scalable infrastructure, AI innovation becomes more accessible and accountable. A system designed for modularity and interoperability ensures that developers can create intelligent, self-sustaining agents capable of handling complex, high-stakes tasks—bringing AI closer to its full potential.
Conclusion: The Path to Fully Autonomous AI
For AI to function without human intervention in high-stakes domains, it must overcome three major hurdles:
Reliability: Addressing bias and hallucinations through decentralized verification systems.
Real-Time Data: Ensuring AI agents have access to continuously updated, high-quality data streams.
Contextual Knowledge: Developing persistent memory models that retain and update knowledge dynamically.
With emerging solutions like Mira Network’s consensus verification and Masa’s Subnet 42, the vision of fully autonomous AI is becoming more feasible. However, significant challenges remain in achieving the balance between autonomy, accountability, and verifiability.
The shift requires more than just better models, it demands a new infrastructure for AI coordination, accountability, and adaptability.
About Cluster Protocol
Cluster Protocol is making intelligence co-ordinated, co-owned & trustless.
Our infrastructure is built on two synergistic pillars that define the future of decentralized AI:
Orchestration Infrastructure: A permissionless, decentralized environment where hosting is distributed, data remains self-sovereign, and execution is trust-minimized. This layer ensures that AI workloads are not only scalable and composable but also free from centralized control.
Tooling Infrastructure: A suite of accessible, intuitive tools designed to empower both developers and non-developers. Whether building AI applications, decentralized AI dApps, or autonomous agents, users can seamlessly engage with the protocol, lowering barriers to entry while maintaining robust functionality.
🌐 Cluster Protocol's Official Links: