Gen AI and data for training AI models in decentralized compute: A match made in heaven
Aug 23, 2024
12 min Read

##Introduction##
Ever wondered how large amounts of data is utilized to train highly intelligent AI models? Where does this data come from? How is it organized? Who controls it? And is there a way to democratize the ownership of data? The following article delves into how the data used for AI model training is managed and how generative AI can play a crucial role in enhancing data management, democratization, and overall training of AI models.
To train an AI model, two main aspects need to be taken care of. Compute and data. Compute is essentially a machine based manipulation of data in order to develop intelligent AI models. Data, on the other hand, is exactly what is fed to these machines to be computed upon. As one may easily guess, the quality of data fed for computation can heavily dictate the abilities, accuracy and intelligence of the AI model trained.
The following article discusses the importance of data management and how advanced technologies like generative AI can significantly enhance quality and accuracy of datasets. With a focus on decentralized methods of compute, facilitated by DePIN technology using a blockchain, the article will also provide an in-depth understanding how Gen AI will support democratization and decentralization of data and also provide a discussion of the future potential of DePIN based compute sharing.
This article begins by providing an understanding of the importance of data management for centralized AI dominators like Google and Amazon, and then progresses into how Gen AI can support and facilitate the growth of decentralized methods of computation.
Why is data management important?
Data management in the AI age is paramount, particularly regarding data quality, accuracy, data security and compliance, and scalability and flexibility.
High-quality data is foundational for AI models, ensuring proper training and validation by preventing biases, errors, and overfitting. This involves meticulous labeling and annotation for supervised learning, rigorous data cleaning processes to remove duplicates, correct errors, and fill in missing values, and standardizing data formats for consistency and integration.
Accurate data supports reliable analytics, leading to better business decisions and enabling real-time or near-real-time analysis for informed, agile decision-making. In terms of security and compliance, robust data management practices include encrypting data at rest and in transit, enforcing strict access controls, and employing techniques like data masking and anonymization to protect sensitive information, particularly in sectors like healthcare.
Compliance with regulations such as GDPR, CCPA, and HIPAA is ensured through maintaining detailed audit trails, logging, and monitoring all data interactions.
Risk mitigation involves implementing security measures to prevent data breaches, conducting regular security audits, and having backup and disaster recovery plans to ensure business continuity.
Scalability and flexibility are essential as organizations collect more data, necessitating scalable data management solutions that handle increasing volumes without compromising performance. This includes optimizing performance through efficient indexing, partitioning, and load balancing techniques.
Integration with emerging technologies like cloud and edge computing is facilitated by seamless data management, ensuring interoperability with various tools and platforms. Future-proofing involves preparing for data growth, technological advancements, and evolving business requirements by maintaining scalable, flexible systems.
These practices ensure long-term sustainability and competitiveness, allowing organizations to continuously adapt and thrive in a data-driven market. In summary, effective data management is crucial for maintaining data quality and accuracy, protecting sensitive information, ensuring regulatory compliance, and providing scalability and flexibility to leverage AI technologies and maintain a competitive edge.

*A chart showing characteristics of quality data*
How do companies ensure data quality?
By practicing crucial data collection and organization protocols. Some of them include -
AI-Powered BI Tools: AI-powered Business Intelligence (BI) tools like Akkio enhance data quality assurance, increasing the efficiency and accuracy of data insights.
Data Collection: Collect high-quality data from reliable sources, setting clear objectives to avoid redundancy. Use data sampling and real-time capture to ensure data representativeness and immediate insights.
Data Labeling: Accurate data labeling is essential for supervised learning. Employ methods like manual annotation, crowdsourcing, and automated labeling, with quality control measures to maintain accuracy.
Data Preparation: Includes cleaning, normalization, and transformation. Imputation techniques handle missing data, while Akkio’s Chat Data Prep streamlines feature engineering and analysis.
Data Storage: Choose between on-premises and cloud-based storage, ensuring robust security and version control to protect data integrity.
Data Quality Monitoring: Implement systems to continuously assess data quality using metrics and anomaly detection. Automated alerts help address issues promptly.
Data Governance and Documentation: Establish clear data policies and document sources, definitions, and lineage. Use data catalogs, like those in Akkio, to facilitate effective data discovery and understanding.
##Data management in the context of DePIN##
Data management in the context of Decentralized Physical Infrastructures (DePINs) introduces unique considerations and differences compared to traditional centralized data management systems.
Here’s how the importance of data management changes when applied to DePINs:
1. Data Quality and Accuracy
Foundation for DePIN Operations
Decentralized Data Sources: Data in DePINs is often sourced from numerous decentralized nodes and sensors, leading to a diverse range of data types and formats. Ensuring the accuracy and quality of this data is critical for the reliable operation of decentralized infrastructures. An example of decentralized methods of sourcing data is Federated learning. To learn more about the various types of decentralized model training techniques, refer to Cluster Protocol’s blog on privacy preserving machine learning techniques.
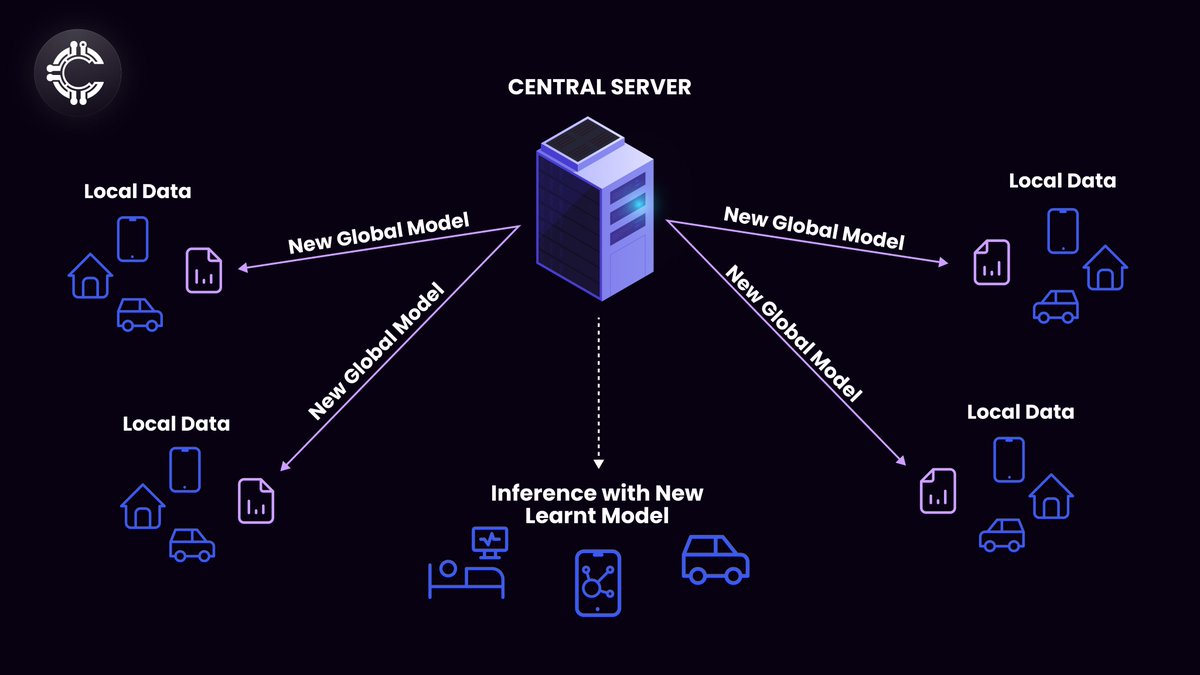
*A diagram representing federated learning, a method by which a model can be trained locally on a home device without needing to share data to a central server*
Consensus Mechanisms: In decentralized systems, consensus mechanisms play a vital role in validating data. Effective data management must include robust protocols for reaching consensus on data accuracy across multiple nodes.
Error Minimization
Decentralized Validation: Data errors and inconsistencies need to be detected and corrected in a decentralized manner. This involves leveraging blockchain or other distributed ledger technologies to ensure data integrity.
Standardized Protocols: Implementing standardized data protocols across decentralized nodes helps minimize errors and ensures consistent data quality, despite the diverse sources.
Improved Decision-Making
Distributed Decision Making: Decentralized infrastructures rely on distributed decision-making processes. High-quality data management ensures that decisions made at the edge are based on accurate and reliable data.
Real-Time Accuracy: For applications like decentralized energy grids or IoT networks, real-time data accuracy is crucial for dynamic decision-making and operational efficiency.
2. Data Security and Compliance
Protection of Sensitive Information
Decentralized Security Measures: In a decentralized context, security measures must be distributed across all nodes. This includes encrypting data at the source, securing communication channels, and ensuring that each node adheres to the same security protocols.
Zero-Trust Architecture: Adopting a zero-trust security model, where no part of the network is inherently trusted, is essential for protecting sensitive data in decentralized infrastructures.
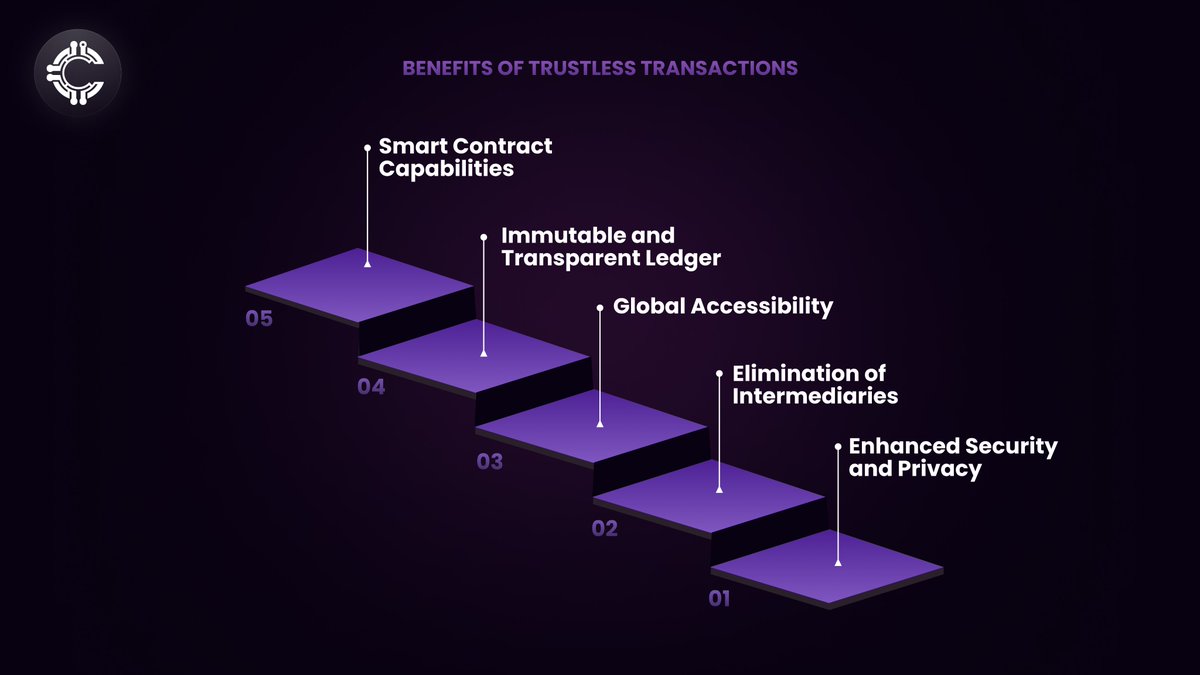
*A diagram representing the benefits of trustless transactions in addition to enhanced security and privacy*
Regulatory Compliance
Cross-Jurisdictional Compliance: DePINs often operate across multiple jurisdictions, each with its own data protection regulations. Effective data management must account for compliance with various local and international laws, which can be more complex than in centralized systems.
Transparent Audits: Blockchain and distributed ledger technologies facilitate transparent audits, helping to demonstrate compliance with regulatory requirements through immutable records of all data transactions.
Decentralized Risk Management: Risk mitigation strategies must be adapted for a decentralized environment. This includes distributed backup and recovery systems to ensure data availability and integrity even if some nodes are compromised.
Distributed Intrusion Detection: Implementing distributed intrusion detection systems helps identify and respond to security threats in real-time across the decentralized network.
3. Scalability and Flexibility
Adaptability to Growth
Horizontal Scaling: DePINs inherently support horizontal scaling, as additional nodes can be added to the network to handle increased data volumes. Effective data management ensures that new nodes integrate seamlessly and maintain data consistency.
Edge Computing: Leveraging edge computing allows data processing to occur closer to the source, reducing latency and improving scalability in decentralized infrastructures.
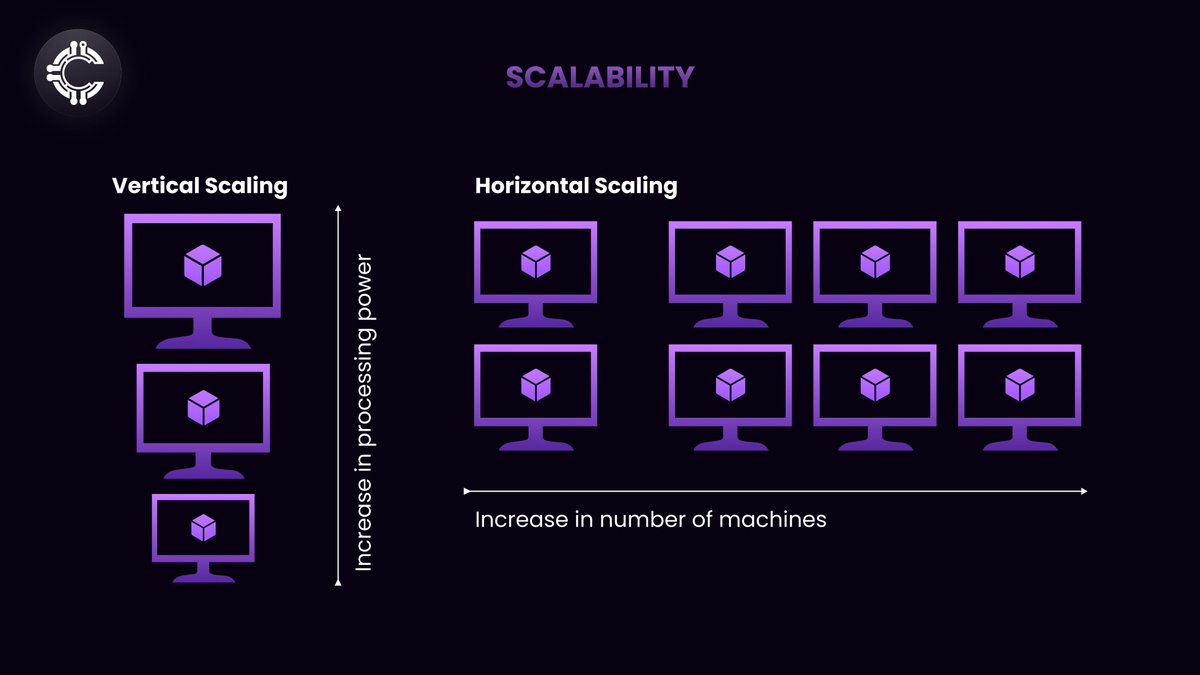
*In the context of DePINs, this translates to increase in the number of nodes of the system rather than machines*
Integration with New Technologies
Interoperability Standards: Ensuring interoperability between diverse decentralized nodes and traditional centralized systems is critical. This includes adopting industry standards and open protocols to facilitate seamless data exchange.
Hybrid Architectures: Effective data management in DePINs often involves hybrid architectures that combine decentralized and centralized components, optimizing for both performance and flexibility.
Future-Proofing
Resilient Architectures: Decentralized infrastructures are inherently more resilient to single points of failure. Effective data management ensures that the system can adapt to node failures, network partitions, and other disruptions.
Evolving Protocols: As new technologies and protocols emerge, data management practices must evolve to incorporate these advancements. This includes staying ahead of trends in blockchain scalability, decentralized storage solutions, and consensus algorithms.
In summary, while the core principles of data management remain important, their application in the context of DePINs introduces unique challenges and opportunities. Decentralized data sources, distributed security measures, cross-jurisdictional compliance, and horizontal scaling are all critical factors that differentiate data management in DePINs from traditional centralized systems.
How Gen AI can help with data management -
Generative AI refers to a subset of artificial intelligence that focuses on generating new content based on learned patterns from existing data. Unlike traditional AI, which typically classifies or predicts based on input data, generative AI creates novel outputs, such as text, images, music, or even code, that mimic or extend the characteristics of the training data.
*Key technical aspects include:*
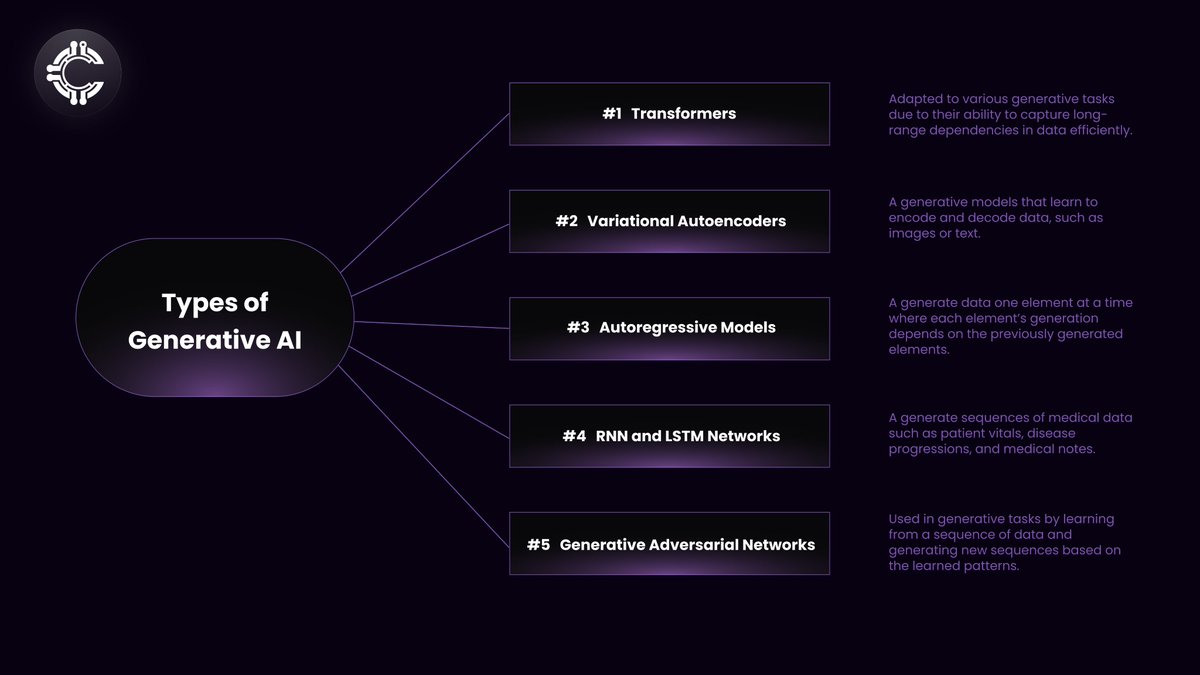
Model Architecture: Generative AI often employs advanced model architectures such as Generative Adversarial Networks (GANs), Variational Autoencoders (VAEs), and Transformer-based models (e.g., GPT, BERT).
GANs consist of two neural networks, a generator and a discriminator, which compete to produce increasingly realistic outputs. VAEs use probabilistic graphical models to generate data by sampling from a learned latent space. Transformer models, especially in natural language processing, generate coherent and contextually relevant text. Below is a graph of the various model architectures employed for generative AI -
Training Process: Generative AI models are trained using large datasets to learn the underlying distributions and features of the data. For instance, a model trained on images learns to generate new images that resemble those in the training set, while language models learn to generate text that follows the patterns and structures of human language. What is the step by step process of training a generative AI model? Here is an overview -
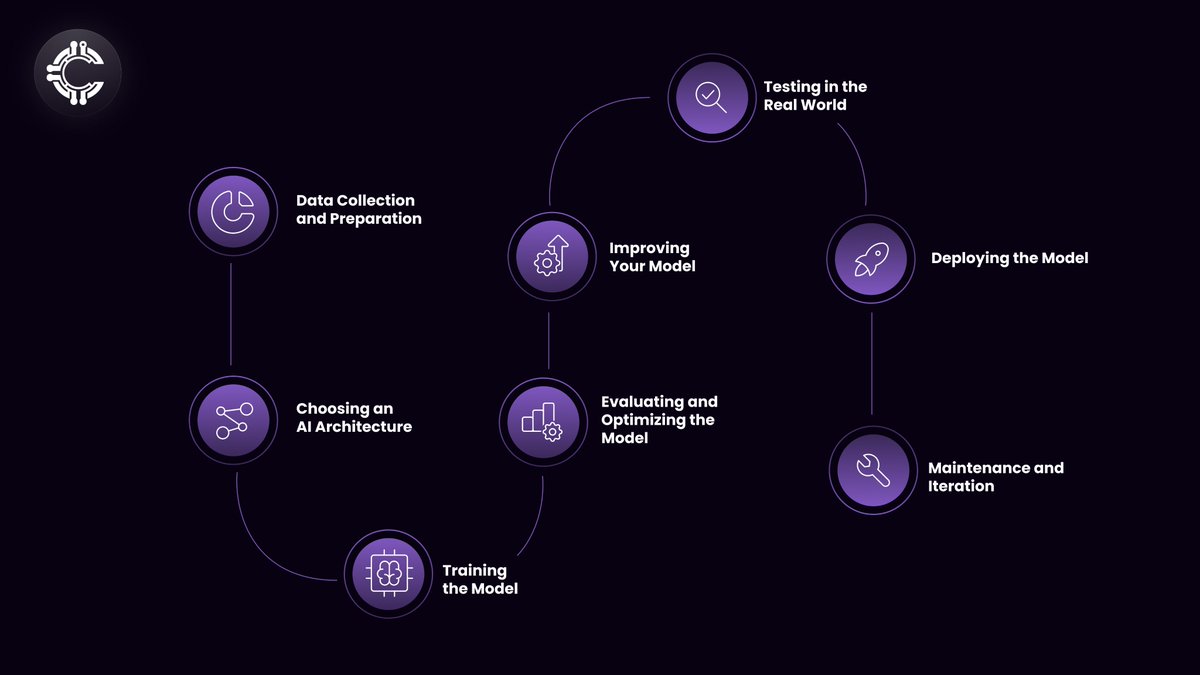
In the context of AI, a range from “supervised” to “unsupervised” learning is observed with “semi-supervised” in the middle. What this simply means is the level of human manipulation done on the data before feeding it for computation. Supervised data is basically data turned into code for computational ease, whereas unsupervised data is when raw data is fed to the machine for computation.
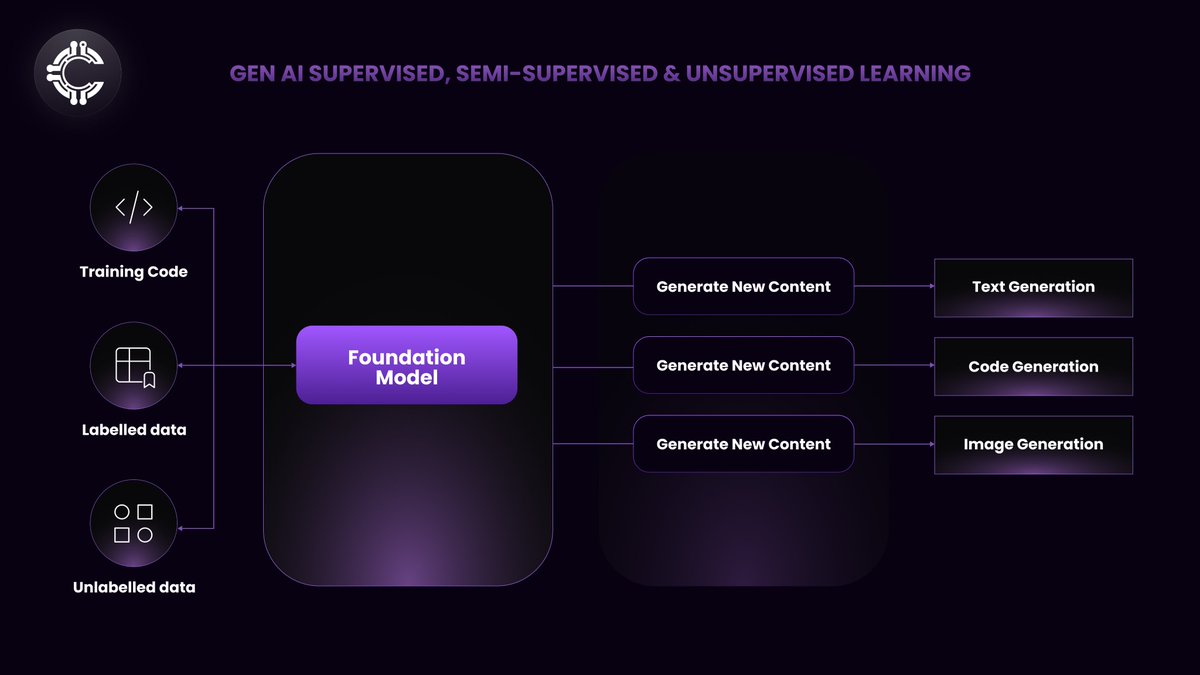
Applications: Generative AI has diverse applications, including data management for training future AI models, content creation (e.g., generating realistic images or deep fake videos), automated writing (e.g., content generation, dialogue systems), and drug discovery (e.g., generating molecular structures).
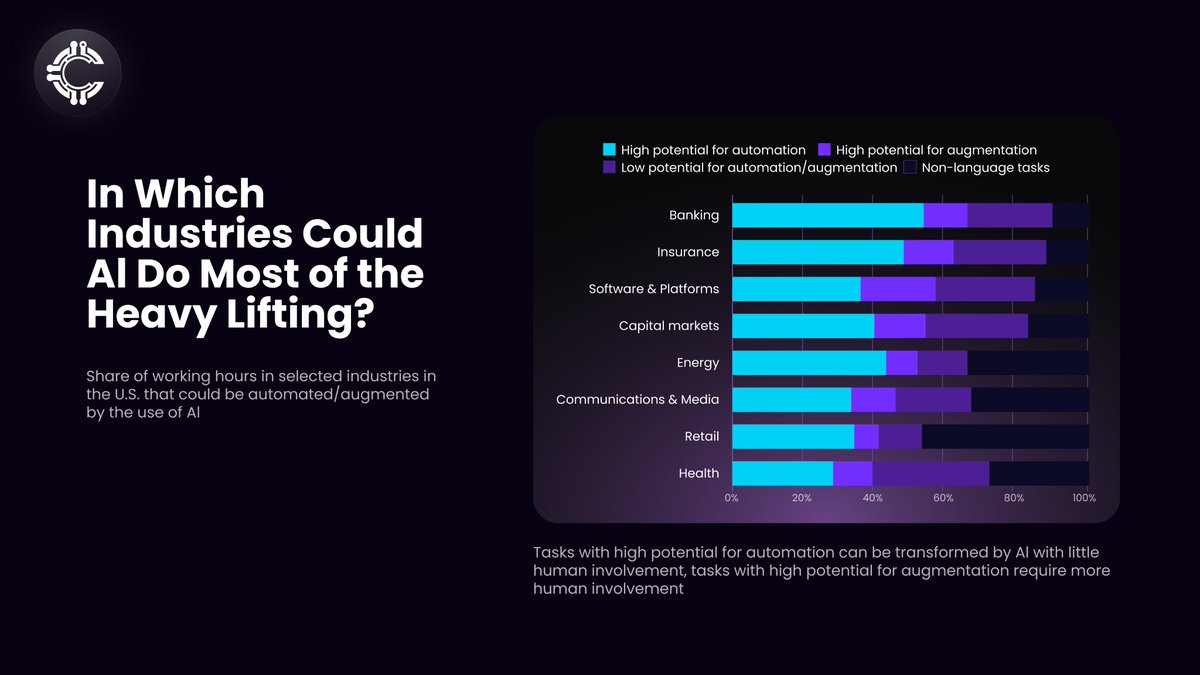
*A chart showcasing the potential automation caused as a result of using generative AI across various industries in the USA.*
Three noticeable trends on Gen AI’s role in transforming data management -
Trend #1: Gen AI makes Natural Language the New Structured Query Language
In 2024, natural language to SQL (NL2SQL) technology is set to revolutionize the way we interact with data. NL2SQL represents a significant advancement in artificial intelligence, enabling individuals with little or no knowledge of traditional SQL programming to query databases and extract insights using plain language.
Democratization of Data:
NL2SQL empowers a wide range of professionals, including business analysts, marketers, field personnel, and healthcare professionals, to access and analyze data independently.
This technology breaks down the language barrier between data and users, promoting inclusivity and enabling non-technical staff to articulate their data needs directly.
Implementation Tips:
Prioritize Accuracy: Focus on generating precise SQL queries, as some large language models (LLMs) handle nuanced or complex questions better than others.
Ensure Efficient Query Execution: Users now expect immediate answers to novel questions, removing the need for pre-engineering data to support conversation-style interactions.
Security Measures: Implement robust access controls, encryption, and user authentication to prevent unauthorized queries and data breaches. Many companies are securely architecting NL2SQL capabilities by using native LLMs inside the database perimeter.
Trend #2: Vector Search for Structured Enterprise Data Gets Serious
Vector embeddings are set to become a game-changer in data warehousing in 2024, with their popularity among practitioners on the rise.
Advantages of Vector Embeddings:
Convert complex data into high-dimensional vectors, capturing semantic relationships, context, and similarities between data points.
Facilitate sophisticated search and retrieval mechanisms, allowing for similarity-based searches and advanced analytics.
Applications:
Enable complex querying and pattern recognition within structured data.
Support a unified system for handling both structured and unstructured data, such as text and images.
Evaluation Criteria for Vector Databases:
Data Latency: Ensure real-time or near-real-time data freshness, crucial for applications needing up-to-the-minute insights.
Query Latency: Assess the speed and responsiveness of the database in retrieving vectors.
Enterprise Capabilities: Implement robust security measures and ensure regulatory compliance.
Support for SQL: Ensure compatibility and ease of integration with existing systems, including NL2SQL capabilities.
Trend #3: GPUs Expand Their Role into Data Management
Graphical processing units (GPUs) have fueled the AI revolution by accelerating complex neural network computations. Their impact is now extending to data management through GPU database architectures.
Drivers of Adoption:
GPUs offer remarkable speed and efficiency due to their parallel processing capabilities, handling large data sets efficiently.
Recent hardware advancements, such as faster PCI buses and more VRAM, have improved overall system performance and responsiveness.
Benefits of GPU Databases:
Support interactive querying without the need for extensive data pipelines, reducing the necessity for lengthy ETL processes.
Enable rapid insights, facilitating quicker and better-informed decision-making.
Cloud Integration:
Leading cloud service providers are integrating GPU capabilities into their infrastructure, democratizing access to GPU-accelerated databases and enabling businesses of all sizes to leverage their benefits.
Key Considerations for Choosing GPU Databases:
Scalability: Efficiently handle vast and growing data sets with a distributed architecture.
Enterprise Capabilities: Ensure robust security, tiered storage, high availability, and connectors to popular tools.
Compliance with Standards: Ensure compatibility with existing systems, such as PostgreSQL.
Partnerships with Industry Leaders: Access cutting-edge GPU technology and engineering resources through strong partnerships with companies like NVIDIA.
Final Note
Generative AI is having a transformative impact on data management by democratizing access, enhancing our ability to uncover new patterns and insights, and prompting a profound reevaluation of traditional data platform construction and maintenance approaches. Additionally, by allowing Generative AI to facilitate the growth of decentralized methods of model training, we are enhancing data privacy, increasing efficiency of training and democratizing access to compute.
The article above discussed the current state of the art in data management of AI model training both in centralized and decentralized methods of computation. We discussed why data management is important for 3 main reasons, one of them being quality and regulatory. Compliance. Furthermore, by providing an overview of data collection techniques like data labeling, the article briefly discussed the various practices companies can adopt to ensure high quality data. Moving on, we discussed data collection and management in the context of DePIN which pose a unique set of challenges and advantages of their own. This was explained in detail using charts and diagrams that represent the current market states. Lastly, we discussed the crucial role and future potential of generative AI in data management and laid out 3 main market trends driven by Gen AI that promise to affect data management the most.
In conclusion, it has been understood that generative AI is having a transformative impact on data management by democratizing access, enhancing our ability to uncover new patterns and insights, and prompting a profound reevaluation of traditional data platform construction and maintenance approaches. Additionally, by allowing Generative AI to facilitate the growth of decentralized methods of model training, we are enhancing data privacy, increasing efficiency of training and democratizing access to compute.
About Cluster Protocol
Cluster Protocol is a decentralized infrastructure for AI that enables anyone to build, train, deploy and monetize AI models within few clicks. Our mission is to democratize AI by making it accessible, affordable, and user-friendly for developers, businesses, and individuals alike. We are dedicated to enhancing AI model training and execution across distributed networks. It employs advanced techniques such as fully homomorphic encryption and federated learning to safeguard data privacy and promote secure data localization.
Cluster Protocol also supports decentralized datasets and collaborative model training environments, which reduce the barriers to AI development and democratize access to computational resources. We believe in the power of templatization to streamline AI development.
Cluster Protocol offers a wide range of pre-built AI templates, allowing users to quickly create and customize AI solutions for their specific needs. Our intuitive infrastructure empowers users to create AI-powered applications without requiring deep technical expertise.
Cluster Protocol provides the necessary infrastructure for creating intelligent agentic workflows that can autonomously perform actions based on predefined rules and real-time data. Additionally, individuals can leverage our platform to automate their daily tasks, saving time and effort.
🌐 Cluster Protocol’s Official Links: