From Surveillance to Sovereignty: The Rise of Private AI
Mar 18, 2025
9 min Read

Intelligence has long been the defining trait of humanity. It is not just raw knowledge or problem-solving ability but the capacity to interpret, adapt, and create. We assume intelligence makes us unique, yet throughout history, it has always been a tool for making life easier.
From the first written language to modern AI systems, intelligence has been about efficiency offloading effort to free ourselves for something greater.
The irony is that intelligence, in its purest form, seeks to remove itself from the equation. The smarter we get, the more we automate. We invented machines to replace labor, algorithms to streamline thought, and now artificial intelligence to take on reasoning itself.
Intelligence pushes forward, and in doing so, it makes itself less necessary.
- AI is not just an extension of our intellect, it is a reflection of it.
- We build machines that think, not because we want to replace ourselves, but because we want to free ourselves.
Now, the line between automation and autonomy is blurring. AI is no longer just a tool for repetitive tasks; it is learning, adapting, and making decisions. Where intelligence was once a uniquely human attribute, it is now something we are teaching machines to possess.
The Dream of Personal AI: More Than Just Assistants
For as long as we’ve imagined the future, we’ve envisioned AI that understands us. Fiction gave us HAL 9000, Joi from Blade Runner 2049, and the digital minds of The Culture novels, machines that don’t just answer questions but anticipate needs, manage complexities, and even offer companionship. The dream has always been about more than convenience; it’s about offloading the overwhelming burden of modern life.
Schedules, finances, health tracking, decision-making being human is exhausting. We crave AI not just to assist us but to augment us, to handle the details so we can focus on what truly matters. The line between tool and partner is fading. The more we rely on AI, the more it needs to know about us, and the more it becomes an extension of ourselves.
Personal AI shouldn't be just a helper, it must be our intellect mirror.
The closer it gets to understanding us, the more we have to ask: how much of ourselves are we willing to share?
The Privacy Dilemma: Intelligence at a Cost
In fiction, AI assistants seem effortless. They know everything about their users, anticipate needs, and respond instantly. But what makes them powerful, unrestricted access to personal data is also what makes them impossible in the real world. A JARVIS-like system would need full control over emails, finances, health records, and even thoughts before they’re spoken.
The real challenge isn’t building smarter AI, it’s building AI that people can trust. Right now, we’re stuck between two flawed options. Handing over data to centralized AI giants gives us seamless, hyper-personalized experiences, but at the cost of privacy. Keeping data local preserves security, but it cripples AI’s ability to adapt, learn, and truly assist. Neither path is sustainable.
AI without trust is just another failed technology.
The problem runs deeper than just technology, it’s a fundamental trade-off between control and convenience. If AI companies continue to collect massive amounts of personal data, they will inevitably face scrutiny, regulation, and resistance from users who don’t want to be constantly monitored.
On the other hand, privacy-first AI solutions struggle to compete because intelligence is inherently tied to the quality and quantity of data they can access. Striking the right balance is the key.
The future of AI won’t be about choosing between intelligence and privacy, it will be about making sure we don’t have to.
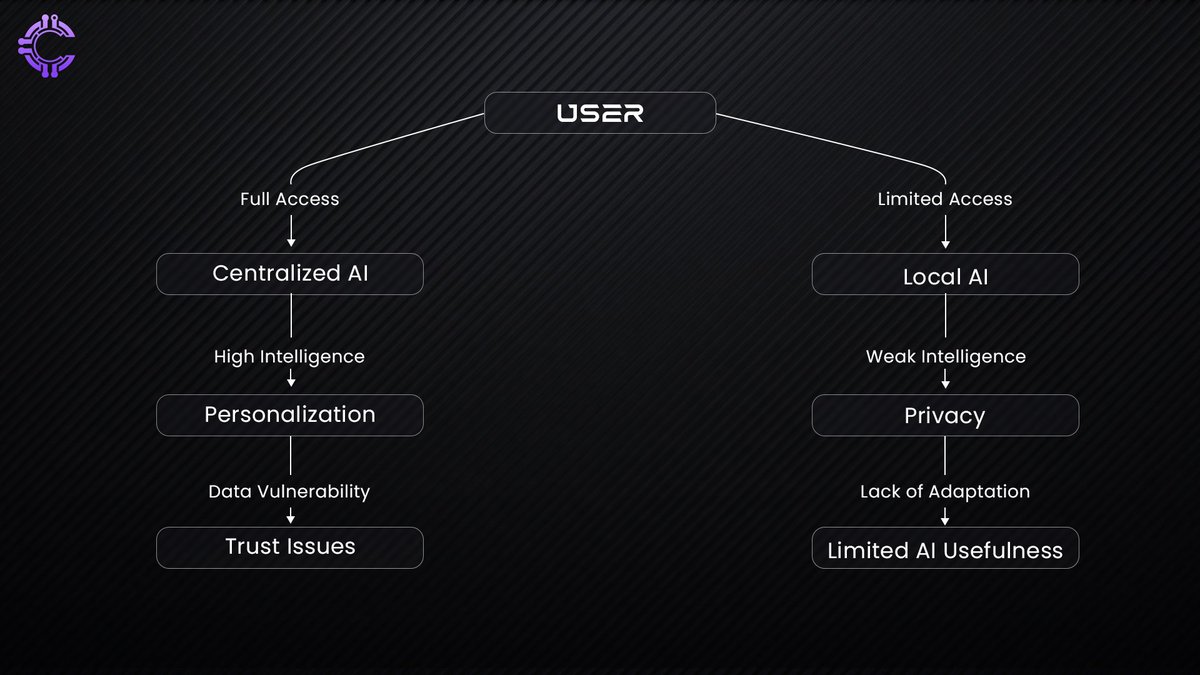
The Data Problem: AI’s Growing Hunger
AI doesn’t just run on data, it devours it. Every model, from the simplest chatbot to the most advanced neural networks, is only as powerful as the information it’s trained on. The smarter AI becomes, the more data it demands. But here’s the problem: most of this data is locked behind the walls of a few corporations. They own the datasets, the compute, and the distribution channels.
This isn’t just a question of efficiency, it’s about control. Whoever controls the data shapes how AI perceives the world. When intelligence is monopolized, so is reality.
The centralization trap: AI today is built on vast, centralized data pools owned by a handful of tech giants.
The surveillance trade-off: The most advanced AI models require users to give up personal data in exchange for intelligence. Privacy becomes the price of participation.
Breaking the cycle: If AI continues to rely on closed datasets, it reinforces digital monopolies instead of democratizing knowledge. The future depends on models that learn without exploiting those who feed them.
Federated Learning & Edge AI
AI has always been about data but most AI models rely on centralized data collection, creating privacy risks and making users dependent on cloud-based infrastructure.
Federated Learning: Local Training, Global Improvement
Instead of collecting raw user data, federated learning trains AI models directly on user devices. The model updates, not the data itself, are sent back to improve the system. This reduces direct data exposure but doesn’t eliminate privacy risks malicious actors can still exploit update patterns to infer information.
More importantly, most federated learning implementations are still managed by centralized companies, meaning users don’t truly own their AI.
Edge AI: AI That Runs on Your Device
Edge AI takes decentralization a step further by processing AI requests directly on user devices phones, wearables, IoT gadgets without needing a constant cloud connection. This enhances speed, reduces latency, and keeps data local.
However, local AI models are weaker than their cloud counterparts, leading to a trade-off between performance and privacy. In practice, most “Edge AI” solutions still offload complex tasks to the cloud, making them more of a hybrid approach than a full departure from centralized control.
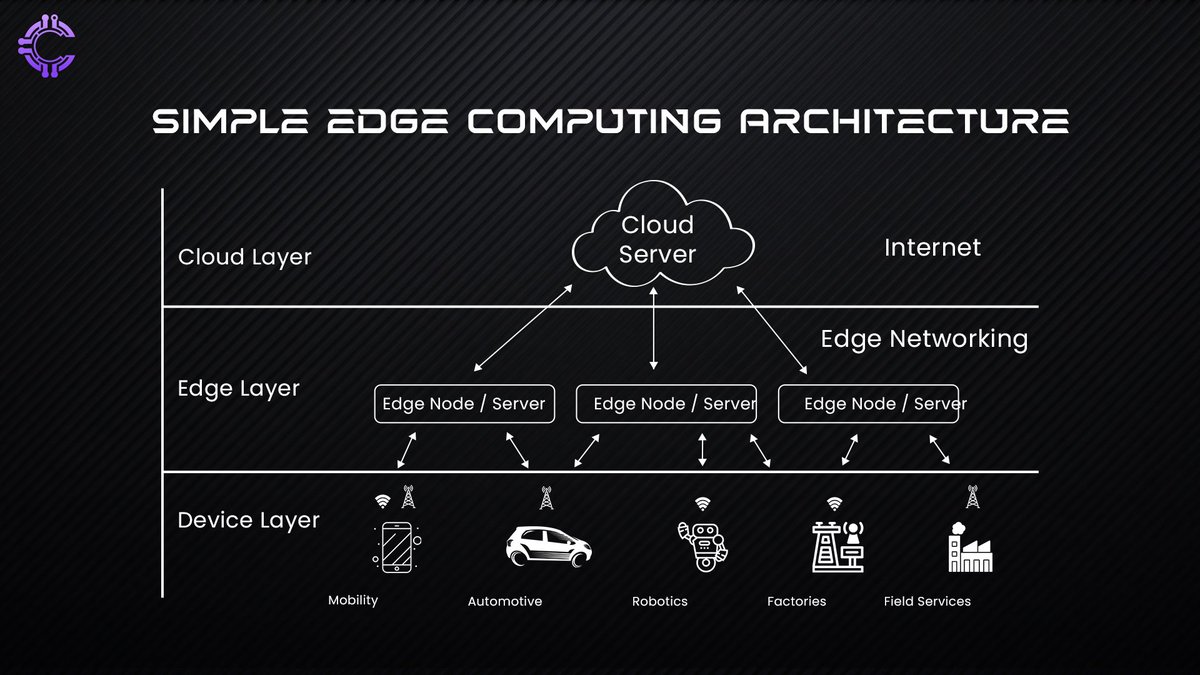
Where Private AI Fits In
Neither federated learning nor Edge AI truly deliver Private AI, AI that is not only local but also entirely under user control. Most implementations today still rely on corporate infrastructure, limiting autonomy. True Private AI would require open models, user-controlled encryption, and decentralized inference, ensuring that AI serves individuals rather than companies. We’re not there yet, but these technologies are incremental steps toward AI that works for the user, not on the user.
Blind Computation: The Missing Piece for Private AI
Private AI is about control - who owns the intelligence, who controls the data, and who gets access to insights. Federated learning and Edge AI help by keeping data on user devices, but they don’t solve a fundamental problem: AI still needs to see the data to process it. Whether it’s a chatbot analyzing messages or a recommendation system predicting preferences, the moment AI starts working, user data is exposed.
Encryption protects data at rest and in transit, but once it’s time to compute, the usual process is decrypt → compute → encrypt.
That decryption step is a weak point, if an attacker, company, or even an AI provider itself gains access during computation, privacy is compromised.
Blind computation changes this equation by allowing AI to process data without ever decrypting it. The AI remains functional, but the raw data remains invisible.
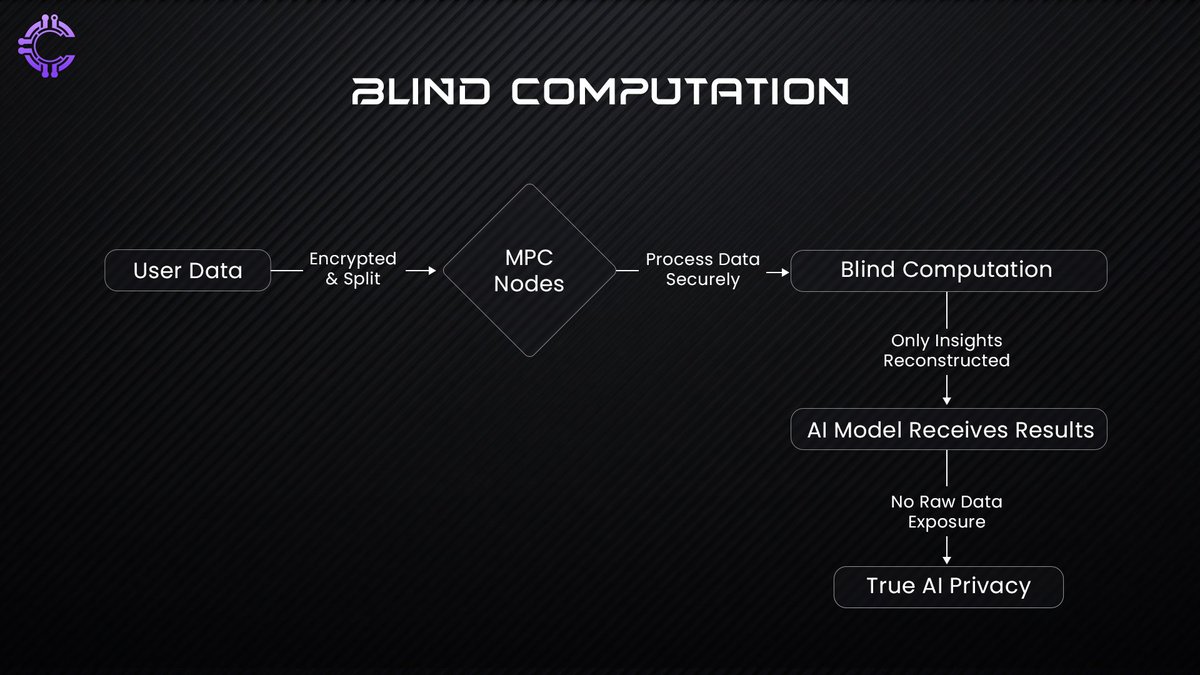
How Nillion Implements Blind Computation
Blind computation is not just a theoretical fix, it’s being implemented in real-world cryptographic systems like Nillion, which leverages Multi-Party Computation (MPC) to break data into encrypted fragments. These fragments are processed independently, ensuring that no single party (not even Nillion itself) ever reconstructs the full dataset.
Data fragmentation: Instead of sending raw data to a central AI, the input is split into multiple encrypted parts.
Independent computation: Each part is processed separately across a distributed network.
Reconstruction of insights, not data: The AI model receives only the computed results, not the original user data.
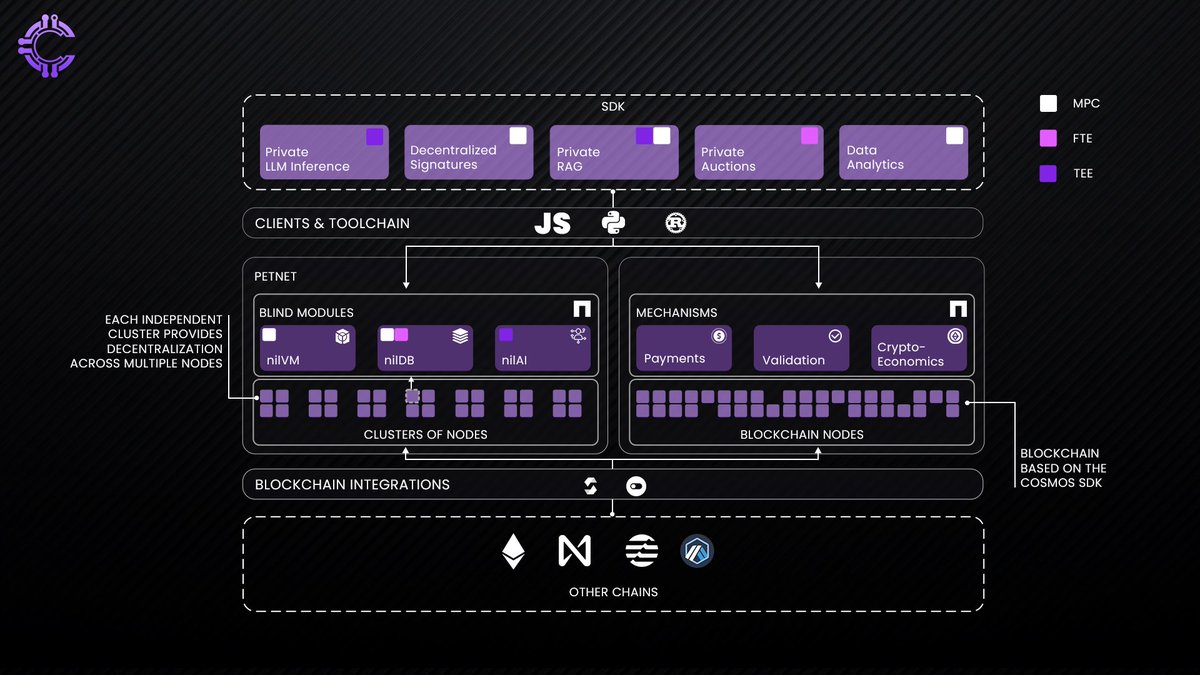
This means an AI assistant could learn about a user’s habits, preferences, or even medical conditions without ever seeing their personal data in its raw form. The AI remains useful and personalized while staying blind to the specifics.
Private AI Without Trade-Offs
With federated learning and Edge AI, the trade-off has always been privacy vs. intelligence, either keep data private but limit AI’s capability, or let AI access data but sacrifice privacy. Blind computation removes this trade-off by allowing AI to compute on encrypted data.
AI can analyze without access: Medical AI can provide diagnoses without seeing full patient histories. Smart assistants can sort emails without reading them. Financial AI can detect fraud without exposing transactions.
Privacy becomes the default: Users no longer have to trust corporations with sensitive data. AI can process information without storing, tracking, or exposing it.
Security without compromise: Traditional encryption protects data at rest, but blind computation protects data even when it’s in use.
For truly private AI, this is the missing piece. Users shouldn’t have to choose between security and usefulness. AI should work without exposing the very information it’s meant to protect. The future of AI isn’t just about intelligence, it’s about trust. If we can build AI that never sees our data, we can finally break free from the cycle of surveillance-driven intelligence.
Private AI in Action
AI will soon become deeply integrated into our lives, but without privacy, its full potential may never be realized. Whether in healthcare, finance, or personal assistants, AI will require vast amounts of data to function effectively. The challenge will be enabling intelligence without sacrificing control.
Healthcare will be transformed. AI-driven diagnostics and personalized treatment plans could revolutionize medicine, but patients and institutions may hesitate to share sensitive data. With blind computation, AI will be able to analyze encrypted patient records without ever accessing raw medical files.
Hospitals across different regions will securely collaborate on research, enabling breakthroughs without compromising privacy. AI will assist doctors without creating new security risks.
Finance will rely on private AI. DeFi and institutional trading will increasingly depend on AI-driven strategies, but market transparency could expose transactions to manipulation. Future AI-powered trading models will execute private transactions, protecting them from front-running and unfair advantages. Privacy-preserving AI could create a fairer financial ecosystem, making decentralized finance viable for large institutions.
AI assistants will evolve. Future AI assistants will manage calendars, messages, and habits without ever storing personal data. With federated learning and blind computation, they will understand users without ever seeing their information. AI will become more personal and intelligent, yet remain invisible when it comes to data access.
Privacy-preserving AI will not just be a feature, it will define the next era of artificial intelligence, where intelligence and security are no longer at odds.
The Future of AI: Intelligence Without Surveillance
AI is no longer just a tool, it is becoming an extension of our lives. But as intelligence scales, so do the risks. Centralized AI, built on mass surveillance, has shown us what happens when power is concentrated in the hands of a few. It leads to walled gardens, data exploitation, and intelligence designed for control rather than empowerment.
The next wave of AI will not be defined by sheer computational power but by something far more important, trust. Intelligence should not require surveillance. Yet, the models that dominate today thrive on data collection, absorbing everything in their reach. The alternative is not weaker AI but a smarter, privacy-preserving system that learns without watching, adapts without exploiting, and serves individuals rather than extracting value from them.
The alternative is clear: an AI future where intelligence remains decentralized, private, and fundamentally in service of individuals rather than corporations. Blind computation, federated learning, and cryptographic AI models have proven that we don’t need to choose between intelligence and privacy. We can have both.
About Cluster Protocol
Cluster Protocol is the co-ordination layer for AI agents, a carnot engine fueling the AI economy making sure the AI developers are monetized for their AI models and users get an unified seamless experience to build that next AI app/ agent within a virtual disposable environment facilitating the creation of modular, self-evolving AI agents.
Cluster Protocol also supports decentralized datasets and collaborative model training environments, which reduce the barriers to AI development and democratize access to computational resources. We believe in the power of templatization to streamline AI development.
Cluster Protocol offers a wide range of pre-built AI templates, allowing users to quickly create and customize AI solutions for their specific needs. Our intuitive infrastructure empowers users to create AI-powered applications without requiring deep technical expertise.
Cluster Protocol provides the necessary infrastructure for creating intelligent agentic workflows that can autonomously perform actions based on predefined rules and real-time data. Additionally, individuals can leverage our platform to automate their daily tasks, saving time and effort.
🌐 Cluster Protocol’s Official Links: